A UML Profile and PostgreSQL Code Generator for the Design and Implementation of SQL Databases
Authors: Erki Eessaar, Sergei Beljakov, Erko Aaberg
This extension is intended for the old version of StarUML - StarUML 5.0
UML is a general-purpose visual modeling language that can be adapted by creating profiles based on its built-in extension mechanism. There exist UML profiles for modeling the logical design of SQL databases. The profiles allow developers to create model elements that correspond to SQL language elements. An example of a rudimentary SQL database logical design profile is StarUML ER diagram Notation Extension.
In case of many integrity constraints, developers have to manually specify the implementation of the constraint in a design model. It complicates the creation of the models and the use the models to generate final code that does not need elaboration. Our approach is to extend UML SQL database design profiles with stereotypes that correspond to domain-independent database design patterns about integrity constraints to raise the abstraction level of models and facilitate generation of code that implements integrity constraints.
In this particular case, we have created a SQL database profile based on the StarUML ER diagram Notation Extension. The main advantage of the profile compared to other SQL database logical design profiles/systems is that it allows high-level specification of the following constraints.
- List of values
- Range of values
- Derived value
- Derived value checking
- Derived value calculation
- External uniqueness
- Disjoint
- Complete
The profile and the accompanying code generator is created based on the specification in the paper:
Eessaar, E., Aaberg, E. Extending UML Profiles to Model Integrity Constraints in SQL Databases. In: Information Modelling and Knowledge Bases XXIII: 21st European Japanese Conference on Information Modelling and Knowledge Bases June 4-8, 2011 Tallinn, Estonia. Eds. Henno, J.; Kiyoki, Y.; Tokuda, T.; Jaakkola, H.; Yoshida, N.. Amsterdam: IOS Press, (Frontiers in Artificial Intelligence and Applications), ISBN: 978-1-60750-991-2, pp. 39 - 58 (2012) [IOS Press]
Download
- Database Design profile 1.0 (13 KB)
- SQL DDL generator for PostgreSQL (7 KB)
- Example model that is created by using the profile and SQL code that is generated based on the model (6 KB)
System Requirements
- StarUML v.5.0. It has not been tested with the new StarUML generation.
Installation
To install the module one has to unpack it and put the folder staruml-erd_extended to the folder of StarUML modules.

The folder must contain subfolders.
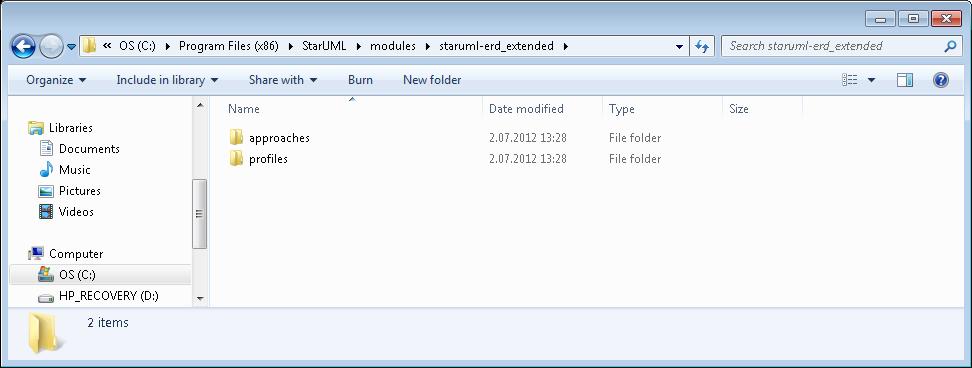
To install the code generator one has to put the folder PostgreSQL to the folder of StarUML generator templates.

Creating Models
To start the work one has to create a new project based on SQL Database Design Approach.

By default the project will be created with one ERD (Entity Relationship Diagram). One can select model elements from the palette that is on the left.
![]()
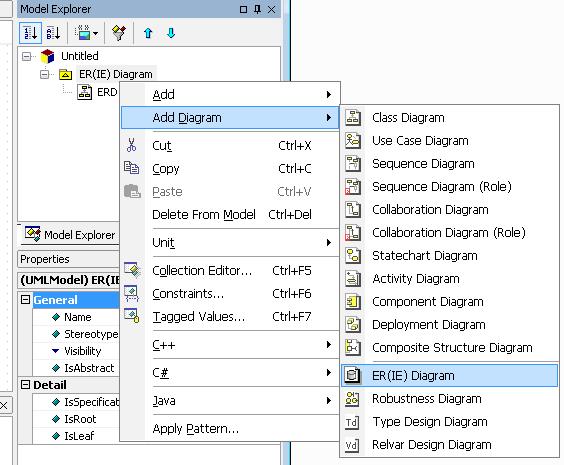
To add a new diagram one has to select a diagram type from the Model Explorer and select Add Diagram.
Stereotypes
Next, we list stereotypes that are specified in the SQL database design profile. Please read about the original profile from the StarUML 5.0 Developer Guide. We use (*) to annotate stereotypes that have been specified as a part of the extension of the original profile. For each such stereotype, we also present tag definitions, the corresponding values of which one has to register during the creation of a new model. All the tag definitions must have at most one corresponding value in case of a correct model.
Stereotypes of Class
- table
- Constraint_set (*) - Class of this stereotype is used to group the model elements, which are created based on domain-independent database design patterns about integrity constraints. Constraints: Constraint_set must not have any attributes. Constraint_set can only have operations, which have stereotypes: List_of_values, Range_of_values, Derived_value, Derived_value_checking, Derived_value_calculation, External_uniqueness, Complete, or Disjoint.
Stereotypes of Association
- identifying
- non-identifying
Stereotypes of Attribute
- column
Stereotypes of Operation
- List_of_values (*) - Operation in Constraint_set. Operation of this stereotype represents an integrity
constraint that restricts possible values in a base table column by listing all possible values.
- table_name - Name of the base table, which contains the column that has this constraint.
- column_name - Name of the column that has the constraint.
- value_list - Comma-separated list of values. All the values must have the same type as the column that has the constraint.
- Range_of_values (*) - Operation in Constraint_set. Operation of this stereotype represents an integrity
constraint that restricts possible values in a base table column by specifying the lower bound and the upper bound of a range of values
(end points included).
- table_name - Name of the base table, which contains the column that has this constraint.
- column_name - Name of the column that has the constraint.
- lower_bound - The lower bound of the range. Its value must have the same type as the column that has the constraint.
- upper_bound - The upper bound of the range. Its value must have the same type as the column that has the constraint.
- Derived_value (*) - Operation in Constraint_set. Operation of this stereotype represents a mechanism, which ensures that for each row r in
a base table T, a value is calculated based on the components of r by using a formula. However, the calculated value is not recorded in T. Instead, it is presented in a view
that is created based on T. It allows us to achieve controlled redundancy. If the value of T is changed, then DBMS ensures that the value of the view will change
accordingly as well.
- view_name - Name of the view that is created to present the derived values.
- table_name - Name of the base table, based on which the view will be created.
- column_name - Name of the column of the view that contains derived values. This name must be different than the names of the columns of the base table, based on which the view is created.
- formula_on_columns - Formula, based on which the derived values are calculated.
- Derived_value_checking (*) - Operation in Constraint_set. Operation of this stereotype represents an integrity constraint to a base table column that contains a derived value. The
constraint ensures that in each row of a base table the derived value in the row is equal with the value that is calculated based on values in other columns of the same table. Additional restriction is that derived
value and values in other columns, based on which it is calculated, must be part of the same row of the table.
- table_name - Name of the base table, which contains the column that has this constraint.
- column_name - Name of the column that has the constraint.
- formula_on_columns - Formula, based on which the derived values are calculated.
- Derived_value_calculation (*) - Operation in Constraint_set. Operation of this stereotype represents a mechanism, which ensures that for each row r in a base table T, a value is calculated
based on the components of r by using a formula. The calculated value is recorded in a separate column c of T. It allows us to achieve controlled redundancy. If the value of T is changed (data is
updated in other column than c), then DBMS ensures that the value in c will change accordingly as well.
- table_name - Name of the base table, which contains the column that has this constraint.
- column_name - Name of the column that contains derived values.
- formula_on_columns - Formula, based on which the derived values are calculated.
- External_uniqueness (*) - Operation in Constraint_set. Operation of this stereotype represents an integrity
constraint, which ensures that combination of values in columns of different tables must always be unique.
Constraints: Tagged values first_column_name and second_column_name must not be equal in case of the specification of an external uniqueness constraint.
- first_table_name - Name of a base table that participate in the constraint.
- second_table_name - Name of a base table that participate in the constraint.
- first_column_name - Name of a column of the table first_table_name, which participates in the constraint.
- second_column_name - Name of a column of the table second_table_name, which participates in the constraint.
- query - SQL query that finds pairs of associated values in columns first_column_name and second_column_name without removing the duplicate rows. The result of the query must be a table that has exactly two columns. The names of the columns must be first_column_name and second_column_name.
- Disjoint (*) - Operation in Constraint_set. Operation of this stereotype represents an integrity constraint, which ensures that each row, which is in the base table that
is created based on the supertype ST, has at most one associated row over all the base tables that are created based on the immediate subtypes of ST.
- supertype_table_name - Name of the base table, which corresponds to the supertype ST in the context of a generalization relationship.
- subtype_table_names - Comma separated list of names of base tables that correspond to the immediate subtypes of ST in the context of generalization relationship.
- Complete (*) - Operation in Constraint_set. Operation of this stereotype represents an integrity constraint, which ensures that each row, which is in the base table that
is created based on the supertype ST, has at least one associated row over all the base tables that are created based on the immediate subtypes of ST.
- supertype_table_name - Name of the base table, which corresponds to the supertype ST in the context of a generalization relationship.
- subtype_table_names - Comma separated list of names of base tables that correspond to the immediate subtypes of ST in the context of generalization relationship.
An Example
Here you can see an example of Entity Relationship Diagram.

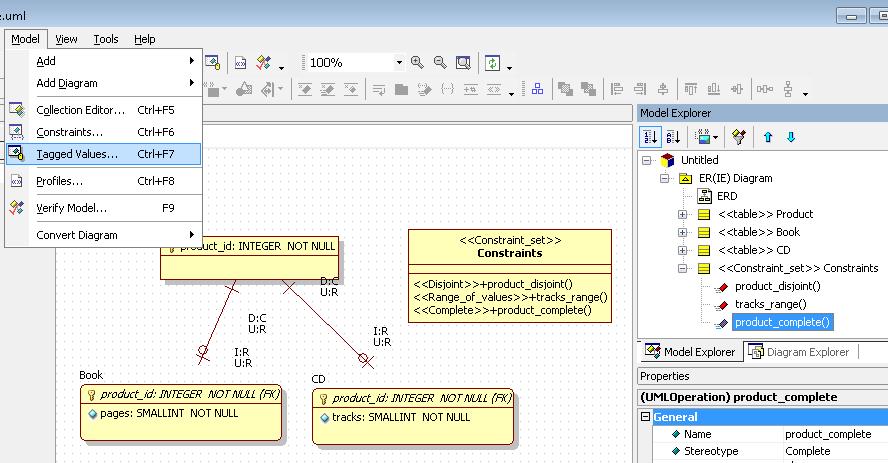
The diagram specifies three base tables – Product, Book, and CD. In addition, three complex constraints have been modeled as stereotyped operations of the stereotyped class Constraints.
Operation product_disjoint, which has the stereotype «Disjoint», specifies the constraint that each product can be either a book or a CD, but not both. The operation has the following tagged values:
- supertype_table_name=Product
- subtype_table_names=Book,CD
Operation tracks_range, which has the stereotype «Range_of_values», specifies the constraint that the number of tracks on each CD must be between 1 and 99 (end points included). The operation has the following tagged values:
- table_name=CD
- column_name=tracks
- lower_bound=1
- upper_bound=99
Operation product_complete, which has the stereotype «Complete», specifies the constraint that each product must belong to at least one of its subtypes (book or CD). The operation has the following tagged values:
- supertype_table_name=Product
- subtype_table_names=Book,CD
If one wants to see/specify tagged values of a stereotyped model element e, then one has to select e in the Model Explorer and after that select Model => Tagged values.
For each column, one can define an initial (default) value.

PostgreSQL(9.0) Code Generator
We have created a code generator that uses database design models as the input. The code generator is able to generate SQL data definition language (DDL) statements for implementing the modelled database as a PostgreSQL database. The results of generating statements have been tested in the PostgreSQL (9.0) Database Management System (DBMS).
To start the generation of SQL DDL statements for PostgreSQL one has to select Tools=>StarUML Generator ...
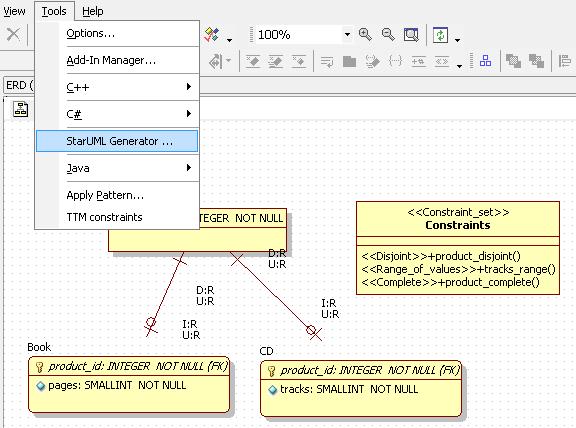
Next, one has to activate PostgreSQL code template and click on the button Next.
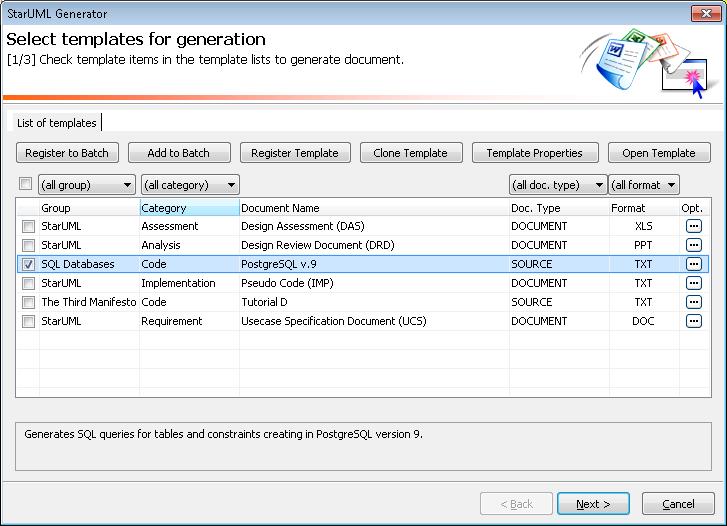
Next, one has to determine the folder and click on the button Next. The system will put generated files to the selected folder. The system generates two files - postgrev9.sql that contains statements for creating database objects (base tables, triggers, etc.) and drop.sql that contains statements for removing the database objects.

To start the generation, one has to click on the button Generate.

The result is following. One has to open the previously specified folder to see the generated files.

In this case the file postgrev9.sql has the following content.
START TRANSACTION;
/* Creates table named "Product" */
CREATE TABLE Product(
product_id INTEGER NOT NULL
);
/* Creates table named "Book" */
CREATE TABLE Book(
product_id INTEGER NOT NULL,
pages INTEGER NOT NULL
);
/* Creates table named "CD" */
CREATE TABLE CD(
product_id INTEGER NOT NULL,
tracks SMALLINT NOT NULL DEFAULT 10
);
/* Disjoint START */
CREATE VIEW v_product_disjoint AS (
SELECT product_id AS col1 FROM Book
UNION ALL
SELECT product_id AS col1 FROM CD
);
CREATE OR REPLACE FUNCTION product_disjoint() RETURNS TRIGGER AS $$
DECLARE resultsNum integer;
BEGIN
SELECT Count(*) FROM v_product_disjoint INTO resultsNum WHERE col1 = NEW.product_id;
IF resultsNum > 1 THEN
RAISE EXCEPTION 'Disjoint constraint "product_disjoint" violation.';
END IF;
RETURN NEW;
END;
$$ LANGUAGE 'plpgsql';
CREATE CONSTRAINT TRIGGER product_disjoint AFTER INSERT OR UPDATE ON Book INITIALLY DEFERRED
FOR EACH ROW EXECUTE PROCEDURE product_disjoint();
CREATE CONSTRAINT TRIGGER product_disjoint AFTER INSERT OR UPDATE ON CD INITIALLY DEFERRED
FOR EACH ROW EXECUTE PROCEDURE product_disjoint();
/* Disjoint END */
/* Range of values */
ALTER TABLE CD ADD CONSTRAINT tracks_range CHECK(tracks BETWEEN 1 AND 99);
/* Complete START */
CREATE VIEW v_product_complete AS (
SELECT product_id AS col1 FROM Book
UNION ALL
SELECT product_id AS col1 FROM CD
);
CREATE OR REPLACE FUNCTION product_complete() RETURNS TRIGGER AS $$
DECLARE resultsNum integer;
BEGIN
IF TG_OP = 'UPDATE' OR TG_OP = 'DELETE' THEN
SELECT Count(*) FROM v_product_complete INTO resultsNum WHERE col1 = OLD.product_id;
IF resultsNum = 0 THEN
RAISE EXCEPTION 'Complete constraint "product_complete" violation.';
END IF;
RETURN NEW;
ELSIF TG_OP = 'INSERT' THEN
SELECT Count(*) FROM v_product_complete INTO resultsNum WHERE col1 = NEW.product_id;
IF resultsNum = 0 THEN
RAISE EXCEPTION 'Complete constraint "product_complete" violation.';
END IF;
RETURN NEW;
END IF;
END;
$$ LANGUAGE 'plpgsql';
CREATE CONSTRAINT TRIGGER product_complete AFTER INSERT ON Product INITIALLY DEFERRED
FOR EACH ROW EXECUTE PROCEDURE product_complete();
CREATE CONSTRAINT TRIGGER product_complete AFTER UPDATE OR DELETE ON Book INITIALLY DEFERRED
FOR EACH ROW EXECUTE PROCEDURE product_complete();
CREATE CONSTRAINT TRIGGER product_complete AFTER UPDATE OR DELETE ON CD INITIALLY DEFERRED
FOR EACH ROW EXECUTE PROCEDURE product_complete();
/* Complete END */
ALTER TABLE Product ADD CONSTRAINT pk_product PRIMARY KEY(product_id);
ALTER TABLE Book ADD CONSTRAINT pk_fk_book_product FOREIGN KEY(product_id) REFERENCES Product(product_id) ON UPDATE RESTRICT ON DELETE CASCADE;
ALTER TABLE Book ADD CONSTRAINT pk_book PRIMARY KEY(product_id);
ALTER TABLE CD ADD CONSTRAINT pk_fk_cd_product FOREIGN KEY(product_id) REFERENCES Product(product_id) ON UPDATE RESTRICT ON DELETE CASCADE;
ALTER TABLE CD ADD CONSTRAINT pk_cd PRIMARY KEY(product_id);
COMMIT;
In this case the file drop.sql has the following content.
START TRANSACTION;
/* Queries for erasing of created objects. */
ALTER TABLE CD DROP CONSTRAINT pk_cd;
ALTER TABLE CD DROP CONSTRAINT pk_fk_cd_product;
ALTER TABLE Book DROP CONSTRAINT pk_book;
ALTER TABLE Book DROP CONSTRAINT pk_fk_book_product;
ALTER TABLE Product DROP CONSTRAINT pk_product;
DROP FUNCTION product_complete() CASCADE;
DROP VIEW v_product_complete;
ALTER TABLE CD DROP CONSTRAINT tracks_range;
DROP FUNCTION product_disjoint() CASCADE;
DROP VIEW v_product_disjoint;
DROP TABLE CD;
DROP TABLE Book;
DROP TABLE Product;
COMMIT;
Limitations
- The diagrams do not provide different visual representations (in addition to stereotype labels) for different types of constraints. UML is a visual modeling language. A possible drawback of the proposed extension is that the extensions are arguably not visually very appealing.
- The profile does not allow us to model two or more different uniqueness constraints for a table. In addition, the generator does not generate code for enforcing uniqueness constraints.
- The profile does not allow us to model views.
- The system does not involve a module for checking the internal consistency of database design models. For instance, one could use nonexistent table names in a specification of a constraint. In this case the generated code will be incorrect.
- The generator is not able to generate code for enforcing foreign-key constraints in case of composite keys (each composite key involves more than one column).
- The generator assumes that the names of foreign key columns are the same as the names of their corresponding primary key columns. If the modeler does not follow this convention, then the system generates incorrect code for enforcing foreign key constraints.
- The generator does not take into account information about compensating actions in case of foreign key constraints that are defined in the model.
- The generator does not check whether the identifiers of database objects, which are used in the models, conform to the rules of PostgreSQL. For instance, one could create a database design model that specifies base table with the name Tabel#. The generator generates statement CREATE TABLE Tabel#(.... However, one cannot execute the statement in PostgreSQL because the name contains symbol "#".
Known mistakes
- If one does not define the primary key for a table, then the system still generates empty primary key constraint for the table.