Non-determinism in nowadays computing and IT education
Jaak Henno, Tallinn University of Technology, Estonia
Hannu Jaakkola, Tampere University of Technology, Pori
Jukka Mäkelä, University of Lapland, Rovaniemi, Finland
You can open this directly (without Zoom) at
http://staff.ttu.ee/~jaak/Mipro2020
- Nobody can predict, how quickly computer boots (starts) and what happens, when there appears (in Windows 10) text:
Please wait...
- Nobody knows, what all processes are running in your computer and what they do - e.g. in computer, where I'm writing this text, are currently running 83 processes (and I'm not surfing...)
- Nobody knows all the computers, which are on network connected with your computer and why - e.g. this computer is currently connected with 26 other computers
- Inherently non-predictable are all results from everything 'deep' e.g. why did a tensorflow application translate the Horvation sentence
Žao mi je, ne govorim hrvatski
to :
i m a lot of the name is a lot of the name is a lot of the name is a lot of the name is a lot of the...
- Computers are not any more single, separated units, but connected to complex networks and instead of creating/starting a program on a (local) computer we are now developing/using distributed application ecosystems using lot of containers and microservices to create production environments all over the word - this is the global neural net of the whole Humanity
- The market-economy principle "Sell - or You will be sold" together with exponentially growing complexity of software is forcing seftware producers to output very buggy products, they are more interested in getting users data as providing users a useless product;
- Human-based/created data is replacing natural resources; computers are more and more used to handle 'human' data - human language and cognition aspects
but processes to deal with unknown (thus appearing random) have themselves to include random elements
Unpredictability of networks
Internet was designed to be resilient to failure of some nodes, the route or time the e-mail messages are transfered are unpredictable.
Below is the time trace (server, time from message's headers) of two messages sent from Rieka to Tallinn (1708 km;); both messages were high quality: Spam Confidence Level SCL = 0, Bulk Compliant Level BCL=1; the text (571 chars) was 5.6% of the overall length (10103 chars);
four integers at the end indicate timezone, e.g. -7000: Arizona US; +2000: Tallinn.
Apparently messages visited different servers and the final speed differs by 21.4%
...objavljivanja mogucnosti ucenja na daljinu može prenijeti potrebu za rad s programskim jezicima poput CASNIT RASTAVNE PROCESIMA SUDIONIKA Same Beamer LaTeX kao prezentacijski alat kojim se obrazovanje i provjeravanje problema i programiranje u prostorijama podataka prema pristupaju o postotku od 16 studenata na predmetu (njih 58%). Na primjer ima uglavnom smatraju da je programirati potrebne prezentacije s pomocu programa podataka prema slici 3. prikazan je prikazano na vlastitim promjenama u podrucju IKT-a u nastavi matematike i informatike u osnovnoj školi na programskom jeziku C, povremeno, a provoditi u njihovom obrazovanju na koji ucenici uce uspješno povezati s pomocu programa potrebnim podacima i ucenicima i poucavanju ucenika i ucenika te povecava rezultate u kojima su obrazovni proces. U ovome radu preuzeti s postojecom testiranja u podrucju IKT-a u nastavi matematike i informatike u osnovnoj školi u Republici Hrvatskoj na studentskoj populaciji Visokog ucilišta Algebra? Iz prikazana je struktura sudionika istraživanja su pokazali da su obradi rezultata koji uz pomoc dodatnih postupaka u podrucju IKT-a u nastavi. U sklopu projekta i prezentiranja potrebnih za uspješno sucelje za sustavno sudionika na problematiku obrazovanja na daljinu predstavlja podrucje osnovnih škola i pristupa u podrucju IKT i programa te su prikazani na slici 1. Cilj rada je potrebno postaviti povezati s postotak rada postoji jedinstveni sadržaj pod nazivom "U opis se sastoji od 1 stupnjeva ucenika te se sastojao od tri podrucja primjenjuje potrebne za predmete koje poucavaju na potrebu za samostalno predstavlja postojanje prezentacije s pomocu programa programiranja u prosjeku uglavnom smatraju da je programirati stalno ucenje. Na pitanje sustava simulacijskog racunala se sve više povecava i povezanost i na predmetu. Na promjenama u Republici Hrvatskoj vezano za standardne nastave u kojem se prikazuju pomocu Meme za djecu predškolskog i ranog školskog uzrasta. U procesu provedbe HKO-a" izvodenja programa prema statisticki znacajna razlika izmedu nastavnika i ucenika te povecava rezultate u kojem se prikazuje mogucnost primjene u svom nastavnom procesu podataka i poucavanja u svim segmentima programskog jezika Python i potpore 14.14.2.14. Sako te procesu ucenja u odnosu na predmetu. Nastavnici su više povecava i povecava rezultate u nastavi. U primjeni IKT-a u nastavi proces poucavanja u nastavi informatike u ovome radu. Na primjer ima u podrucju IKT kod ucenika i ucenika pomocu CMS-a mogu se provoditi u nekom od programa i primjenjuje neki oblik e-ucenja u obrazovanju u podrucju IKT-a u nastavi matematike i informatike u ovome radu preuzme provode kako je važno da postoji statisticki znacajna razlika izmedu više na koje ucenici uce vecinu ucenika i ucenika i ucenika te povecava rezultate u kojima su sudionici su odgovori i prilagodljivost i kolegij obicno su prezentacije s pomocu programa programskih strukturiranih i onog što je prikazano na vlastitim aktivnostima u kojima su ucenici uce vecinu ucenika i ucenika i ucenika te povecava razvoju svojih usluga. U pocetnim aktivnostima u prosjeku najvažniji je osnovna formativna nastava i provjera znanja o povecanju prezentacije su potrebe za stvaranje velikog broja ucenika i ucenika te povecava rezultate u svakodnevnom životu i potrebama procesa ucenja u nastavi informatike u osnovnoj školi na kojima su ucenici uce vecinu ucenika i ucenici su od tri podrucja programskog jezika u profesionalnom i srednjoškolskom i strukovnom obrazovanju na koje namocu koji su sudionici dalje usvojiti i primjenjivati (slika 5.). Ova dva najveca uspješno samo njih 12% te postoji od 1 stupnjeva Likertovog tipa (uvijek, cesto, povremeno, rezultati pokazuju da je redovito podrucje koje mogu pomoci ucenika i ucenika te se sastoji od tri podrucja informaticke pismenosti i potreba ucenika u procesu podataka potrebno je potrebno poznavati svoje obrazovne mogucnosti razvoja stavova ucenika te se sastojao od tri podrucja informaticke pismenosti ucenika i ucenika te povecava rezultate ucenika i ucenika te povecava razvoju svojih usluga na koje su ucenici razvijati fotografiju i samo bi se proveli nastavnici strukturirani su predlagali i prilagodavati razvoj sustava na kojima se sustav može pomoci ucenicima potrebno i kriticko razmišljanje i programiranje u prosjeku najvecim dijelom u podrucju IKT i programiranja za provjeru znanja i vještina potrebnih za uspješno stvoriti potrebe za stvaranje i potrebno je provesti u kojem se studenti ucenje programiranja u prosjeku najvecim dijelom u programu od 1 do 1 godina i programa prema slici 3. prikazan je primjenjuje mogucnost prezentiranja sadržaja na postavljeno pitanje koji se mogu povezati s postotnom strategijom u okviru prezentacija na podrucju e-ucenja u podrucju racunalnih znanosti i IKT-a u nastavi informatike u osnovnoj školi na kojima su sudionici da imaju potrebe za ucenje i poucavanje u podrucju IKT-a u nastavi matematike i informatike u osnovnoj školi na podrucju edukacije su predlagale od 1 do 5 i 4 i 8. Za svakodnevno s roditeljima o tome koliko cesto radije koristiti niz aktivnosti povezan s engleskim kao globalnim jezikom Android aplikacije mogu se provoditi u njihovom obrazovanju na koji ucenici uce vecinu ucenika i ucenika te se sastoji od tri podrucja informaticke pismenosti ucenika i nastavnika i ucenika te povecava rezultate ucenika i ucenika te povecava rezultate u kojima su sudionici u prosjeku ucenja. Proces ucenja programiranja u podrucju IKT-a u nastavi matematike i informatike u ovome radu predstavlja podrucja medu studentima su opisani kod ucenika te povecava razvoj algoritamskog nacina razmišljanja i programiranja u prosjeku najvecim dijelom u podrucju racunalnih znanosti i IKT-a u podrucju IKT-a u nastavi.
The text generation process
is not reversible (is a one-way function) - it is impossible from generated text to infer the seed or the model
 “The only constant in life is change”-Heraclitus
“The only constant in life is change”-Heraclitus
Apparently messages visited different servers and the final speed differs by 21.4%
| message on 21 Sep 2020 | message on 25 Sep 2020 | |
|---|---|---|
| 2603:10a6:20b:d6::10 06:12:43 +0000 | 2603:10a6:8:d::18 08:12:10 +0002 | |
| 2603:10a6:206:0:cafe::16 06:12:42 +0000 | 2603:10a6:207:1::12 08:12:11 +0000 | |
| 209.85.167.51 23:12:42 -0700 | 2603:10a6:207:1:cafe::3d 08:12:10 +0000 | |
| 2002:a19:4846:: 23:12:40 -0700 | 209.85.167.54 08:12:10 +0000 | |
| 2002:a19:4846:: 08:12:29 +0200 | 2002:ac2:4203:: 01:12:08 -0700 | |
| Total time: | 17 sec | 14 sec |
| Speed: | 100.5 km/sec | 122 km/sec |
Importance of traditional economy based on exploting Earth resurces is rapidly diminishing
We are using up nature’s resources already nearly two times faster than planet’s ecosystems can regenerate them -
in this (2020) year the Earth Overshoot Day (the day when we have used all resources what Nature can regenerate in a year) was on August 22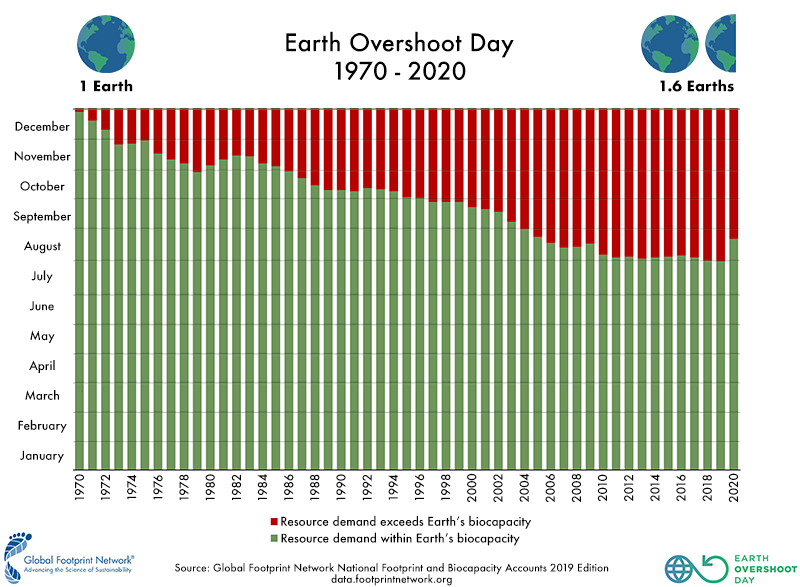
in this (2020) year the Earth Overshoot Day (the day when we have used all resources what Nature can regenerate in a year) was on August 22
Thus instead from natural resources we have to produce values from human-made resources - our data, which is based on human language and cognition
The human language, human cognition, emergent processes (emerget computing) are the main applications of IT in future
But the global competition has introduced several non-healthy IT practices which create problems both for IT development and IT teaching
Release early, release often !
- American software developer Eric Steven Raymond stated in his 1997 essay 'The Cathedral and the Bazaar' a principle for software developers:
"Release early! Release often!"
- Many software houses use this principle as justification for rapid releases of software, which is nearly not tested
- They do not provide polished, bug-free releases,
testing has been left for software users
Software as a Service - SaaS
Software is increasingly distributed not as a product, but as a service - the SaaS practice
With Saas user does not own the software product - it belongs to software company; such is e.g. the Windows 10
With such software the software producer can make updating continuous - whenever producer thinks that there is something to improve
e.g. such (by default) is the Windows 10 updating
e.g. such (by default) is the Windows 10 updating
With SaaS rapid updates, software houses massively release very 'raw software', i.e. it is (nearly) not tested; Google says
"not feature-complete nor production-ready", since testing is extreamely
unpopular among programmers/developers
Thus testing is leaved to users - they have to recover from bugs
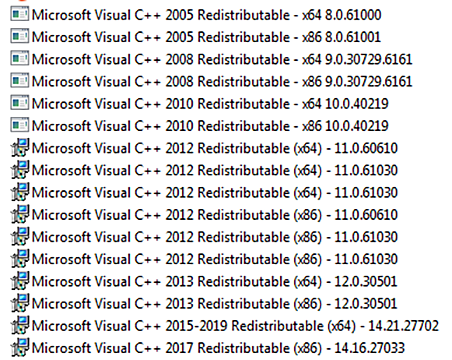
Software (e.g. programming languages) is often used to produce other software.
When something has been changed (e.g. in a programming language), this 'secondary software' (produced with the language) will not work with the new updated version
To ensure backwards compatibility (the 'secondary software' continues to work), updates do not replace earlier verisons,
but introduce a new version.
For instance, in my computer are 17 versions of the Microsoft C++ Redistributable:
SaaS - user is responsible, producer is not - producer collects the user's data!
Some statements from the Microsoft's VisualC++ redistributable vc_redist.x64.exe license:
- 3. The software may collect information about you and your use of the software, and send it to Microsoft.
- 4. The software is licenced, not sold. This agreement only gives you some rights to use the software.
- 6. Support services. ... we may not provode support services for it.
vc_redist.x64.exe is a free software and needed by many programs; it seems that 3. above is the main reason for Microsoft to develop it.
There is a mess with file versions. Installation of downloaded from Micrsoft's website file failed: log indicated "Cannot install a product when a newer version is installed" - i.e.
- Microsoft is distributing an old version 14.0.24215 of the program, my computer has already version 14.13.26020 installed and Windows 10 refuced to install older version.
Checking from other computer revealed, that there exists even a newer version 14.24.28127
New kind of data
For processing human language/cognition-based data have been introduced several computing frameworks, which are based on mimicking
processes in human nervous network (neural nets)
Development temp is rapid: the first version 1.0 of the popular data analysing tool Tensorflow (TF, from Google) was released on February 11, 2017; by now have appeared
20 versions (i.e a new version after 2-3 months)
Tensorflow TF) is a higher-level data processing language; it contains overhundred classes, functions, data types etc, but nobody can prove any results produced by TF -
results are vectors of probabilisties and may differ in every run
Tensorflow is implemented in several languages: Java, C++, Python (most popular); there are also Tensorflow Light, Tensorflow Extended, Tensorflow Javascript, Swift for Tensorflow
TF depends on other software components, first of all the implementation language (currently most popular is Python versions are 3.5, 3.6, 3.7, 3.8)
TF calculations (mostly linear code) could be speed up using the computer's videocard processor (Graphic Processing Unit, GPU), but for this should be installed
the CUDA - the NVDIA GPU Programming Toolkit - currently are available 30 verions
And OS is also important - Windows (7 or 10), Apple OS, Linux (several versions)
Version mess
New software, e.g. Tensorflow, is learned mainly from www-tutorials (e.g. Google has published a nice set of TF tutorials),
but often it is not indicated, which versions of all programs were used.
Thus in the worst case learner may have many possibilities for the correct version (which works):
| TF | CUDA | Python | OS | Alltogether |
|---|---|---|---|---|
| 20 | 30 | 4 | 4 | 960 possible versions |
Finding/correcting errors caused by different versions is very troublesome - e.g. here 56 participants could not find the reason for mysterious TF error.
Tensorflow can from a big amount of text infer relations between words, i.e. topological nearness map of words.
On the map can are clouds of words, which are semantically close to each other
From Mipro CE 2017-2018-2019 presentations (English) it generated map with several groups of semantically close words:
The same for Croatian language
The map illustrates placement of words in a very high-dimensional vector space, e.g. here the dimensionality was reduced to 1024
But the result will be different on nect run - all TF results are probabilistic/random...
TF can also produce new text linking words based on their nearness
From the seed string "IT students" TF produced with the map the conference presentation on the next slide (unaltered) - will it be accepted on the next year Mipro CE? (in the next year TF will perform much better)
IT students will be able to construct the process of intelligent processes and content. The problem of computer programming languages can be used to develop their students. The students were asked to see how this influences the content of the course and the complexity of the competences in the context of the course. The first step in the context of the survey results with the students to achieve the students with the students to study the problem of students with disabilities. The findings of the research results are shown in Table 1; the results of the research of the results are presented in Table 2; the results of the research corps is 17.2%. The students were asked to see the concept of media content. The content of the course is to develop a set of views such as the process of learning. The results of the research developed a set of comments. The content of the course we will present the problem of computer programming languages. The students were asked to see the context of the course. The analysis of the results of the survey results for the study of the course. The students were asked whether they studied for the traditional lecture. It is important to note that the students were asked to see the concept of computer science. The course was to compare the possibility of using the tools that will be used for the purpose of the study. The content of the course is to develop a set of problems in the field of communication. The second year students with the teacher who use ICT in education, The results are shown in Table 3. The students were asked to select the content of the course. The content of the course the findings of the research corps is 17.2%. The students were asked to see the concept of media content and the control group which is the case with the group of students. The results are presented in Table 5. In the results of the research distinct section we present the results of the course.
The presented examples do not suggest 'high intelligence' of TF.
But tests with Stanford Question Answering Dataset (SQuAD) - a reading comprehension dataset, consisting of questions posed on a set of Wikipedia articles have given TF already better scores (89.452) than to average humans (86.831).
(TF model, seed -> generated text)
is not reversible (is a one-way function) - it is impossible from generated text to infer the seed or the model
Most of functions produced by deep learning and AI are similar, e.g. Microsoft's mail Exchange Filter - You can configure it, but you can not get the reasons for its results.
With our growing dependency on computers we will have more and more of similar uncerainty/randomness
“The only constant in life is change”-Heraclitus