Antlr 3-s on realiseeritud rida uuendusi, mille tõttu neis loengutes Antlr 2 formaadis esitatud näited võivad vajada ümbertöötamist (selleks on loodud ka automaatne töövahend ANTLR v2 to v3 converter ). Järgnevas on kirjeldatud Antlr3-e sisendfaili struktuur ja selle tähtsamad erinevused Antlr 2 -faili struktuurist.
1. Lekser (leksikaanalüsaator, skanner) ja parser (süntaksianalüsaator) kirjeldatakse koos, samas failis; lekseemide nimed peavad algama suurtähega, mitteterminalid - väiketähega; fail algab grammatika nimega ja see peab kokku langema failinimega, seega Antlr-3 faili Expr.g (.g -grammar - standarne failinime laiend) sisaldab näiteks ridu
grammar Expr; omist : ID '=' avald; avald : ID | INT | ...
; ID : ('a'..'z'|'A'..'Z')+ ; INT : '0'..'9'+ ; NEWLINE:'\r'? '\n' ; WS : (' '|'\t')+ {skip();} ;
Eelnevas omist avald on mitteterminalid (süntaksigrammatikast), ID, INT, NEWLINE, WS (WhiteSpace)- lekseemid, produktsioonide noole  asemel on : .
asemel on : .
Lekseemide moodustamisel on mõnikord kasulik tähistada lekseemi kuuluvate regulaarsete avaldiste alamavaldisi (mis ise ei ole lekseemid, kuid on mitme lekseemi osad, s.t. neid oleks otstarbekas tähistada mitteterminaliga), Antlr3-s selliste abilekseemide ette tuleb lisada võtmesõna fragment, näit
fragment LETTER : '0'..'9' ;Selle abilekseemi abil on näiteks lihtne deklareerida lekseemi ARV, mis võib olla nii täis- kui ka reaalarv:
fragment INT : '0'..'9'+ ;
ARV : INT ('.' INT)?
(? näitab, et eelnev osa võib ka puududa).
Leksikaanalüüsis (lekseris) võib väljajäetavad lõigud märkida semantilise tegevusega skip(); näit
WS : (' '|'\t')+ {skip();};
- s.t. nn. whitespace-märgid (tühikud) jäetakse edasisest analüüsist välja (kui neid siiski võib edaspidi tarvis minna, siis saab kasutada ka nende suunamist nn mittenähtavasse kanalisse: $channel=HIDDEN;).
Parseri java-tekstile lisatavad java-koodi osad (deklaratsioonid jne) tuleb kirjeldada osas @members, (sama, mis Bison-is %{...%} )näiteks
@members {
/* nimede tabel - nimele vastab väärtus */
HashMap memory = new HashMap();
}
Et eelnev toimiks, peab enne olema parserile
lisatud ka klassi HashMap importimine:
@header {
import java.util.HashMap;
}
Lähteteksti terminaalsed stringid (Antlr-i terminoloogias - literalid) tuleb alati esitada apostroofide, mitte jutumärkide vahel:
omistamine: ID ':=' avaldis ';' ;
Grammatika metasümbolite '?' (0-1 kordus, s.t. kas on või puudub, eespool [ ]), '+' (kordus 1,2,...) ja '*' (kordus 0,1,2,...) kasutamisel pole vastavat avaldist tarvis võtta sulgudesse, metasümbol kirjutatakse otse vastava mitteterminali järgi, näit Java kompilatsiooniühiku võib kirjeldada nii:
compilationUnit : annotations? packageDeclaration? importDeclaration* typeDeclaration+ ;
Kui tahetakse lasta koostada ka abstraktse üntaksi puu AST (Abstract Syntax Tree), tuleb lisada
options
{
output = AST;
}
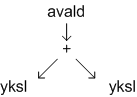 Abstraktse süntaksi puu moodustamisel toimub sageli puu lihtsustamine ja tippude ümberjärjestamine; puu moodustamisel (parseris) tähendab ! mingi lekseemi või literali järel, et see jäetakse puust välja, näiteks avaldistes esinevad sulud pole pärast puu struktuuri leidmist, s.t. pärast süntaksianalüüsi enam vajalikud ja need jäetakse tavaliselt välja; ^ lekseemi või literali järel tähendab, et see tuleb paigutada vastava alampuu tippu, näiteks operatsioonimärgid tavaliselt paigutatakse alampuu tippu, seega parseri produktsioon
Abstraktse süntaksi puu moodustamisel toimub sageli puu lihtsustamine ja tippude ümberjärjestamine; puu moodustamisel (parseris) tähendab ! mingi lekseemi või literali järel, et see jäetakse puust välja, näiteks avaldistes esinevad sulud pole pärast puu struktuuri leidmist, s.t. pärast süntaksianalüüsi enam vajalikud ja need jäetakse tavaliselt välja; ^ lekseemi või literali järel tähendab, et see tuleb paigutada vastava alampuu tippu, näiteks operatsioonimärgid tavaliselt paigutatakse alampuu tippu, seega parseri produktsioon
avald: yksl (('+'^|'-'^) yksl)
moodustab märgi '+' leidmisel mitteterminalile avald kõrvaloleva puu.
Antlr kasutab analüüsis täiustatud LL-strateegiat (nn. LL(*) ), mis võimaldab analüüsida ka grammatikaid, mis pole LL(k) mitte mingi fikseeritud k väärtuse korral.
 ©2004
Jaak Henno
©2004
Jaak Henno