Tartu Ülikoolis loodi Ülo Kaasiku eestvedamisel ülipilasrühm masintõlke uurimiseks juba 1957/58 õppeaastal, kui ülikoolil polnud veel arvutit. Rühma eesmärgiks oli tutvuda masintõlke-alase kirjandusega ja konkreetselt uurida matemaatika-alaste tekstide tõlkimist vene keelest eesti keelde. Koostati 1350 sõna sisaldav vene-eesti matemaatika-alane sõnastik, koostati tõlkealgoritme ja kaitsti mitu selleteemalist diplomitööd (A. Korjus, T. Kala) ja kui Tartu Ülikool sai 1959 a elektronarvuti Ural-1, hakati uurima matemaatiliste tekstide tõlkimist ka teises suunas, eesti keelest vene keelde. Ü. Kaasiku, T. Akkeli, A. Korjuse ja A. Laumetsa artiklis "Matemaatilise teksti tõlkimine vene keelest eesti keelde", Loodus ja Matemaatika 2, Tallinn 1960 on esitatud näidislause "Эта теорема называется обычно теоремой существования решения дифференциального уравния при заданном начальном условии", mille tõlge pidi koostatud algoritme kasutades tulema selline "Seda teoreemi nimetatakse differentsiaalvõrrandi lahendi olemasolu teoreemiks antud algtingimuste juures" - mitte päris sile, aga siiski arusaadav. Kuid peale peamiselt morfoloogia-alaste liigituste (T. Tobiase artiklis "Eesti keele lauseliikmetest", Сообщ.я по машинному переводу 1, EKKI, Tallinn 1962, 18-23 leiti eesti keele verbidele 79 käändkonda) praktiliste tulemusteni ei jõutud.
Masintõlge on olnud probleem, mida on ammu püütud mehhaaniliste seadmete abil lahendada. Pühapäeval, 24.ndal veebruaril 1924 ilmus ajalehe "Waba Maa" numbris 46 artikkel "Kirjutusmasin-tõlk", milles teatatakse:
"Hiljuti ilmus ühes kohalikus ajalehes teade, et Londonis on üles leitud masin, millega võõra keele tundmata tõlkeid igasugusest keelest võib teha. Ehki küll meie aeg iga päev uusi üllatusi pakub, siiski leidis see teade vist vähe uskujaid. Kuid üllatus oli veel suurem, kui neil päevil meile hr. A. Waher oma tõelist kirjutusmasin-tõlgi mudelit demonstreeris. Ühtlasi tõendas ta, et Londonis sarnast masinat üles leitud pole, milleks tal ka vastav tõenduskiri Londoni saatkonnalt oli ette näidata.
Hr. Waher olla ligi 10 aastat oma ülesleiduse kallal töötanud ja nüüd enam-vähem oma tööga nii kaugele jõudnud, et pooleteise kuu pärast proovi masin-tõlgi esitada võib."
Waheri kirjutusmasin-tõlgi edasise saatuse kohta pole andmeid, ilmselt see siiski ei hakanud tööle.
Kui ilmusid elektronarvutid, oli masintõlge üks esimesi probleeme, mida püüti nende abil lahendada. Juba 1947 aastal esitas Warren Weaver oma kirjas Norbert Wienerile, et arvuteid peaks kasutama tõlkimisel. Mõne aastaga loodi masintõlkega tegelevad uurimisrühmad mitme USA ülikooli juures ja juba 1954. aastal toimus New Yorgis arvuti abil vene keelest inglise keelde tõlkimise demonstratsioon (hoolikalt valitud 49 näidislausega!), seega on arvuti abil tõlkimissüsteeme uuritud ja leiutatud juba viiskümmend aastat - sama kaua, kui on eksisteerinud elektronarvutid.
Arvutitõlkega tegeldi ka Nõukogude Liidus. Juba 1930-ndatel aastatel olid armeenlane Georges Artsrouni ja venelane Pjotr Trojanski taotlenud patente "tõlkivale masinale"; Trojanitski esitas mitte ainult kahekeelset mehaniseeritud otsimisüsteemiga sõnaraamatut, vaid ka vastavate grammatiliste vormide leidmist (vahekeelena oli esperanto). Kui Nõukogude Liidus hakati tootma arvuteid, hakati uurima ka masintõlget, siit sai alguse ka sellealane töö Tartu Ülikoolis.
Kuid seni on masintõlge kõige tuntumaks saanud anekdootlike näidistega: kui arvuti oli tõlkinud ingliskeelse lause "The spirit was willing, but the flesh was week" (piiblitsitaat: hing oli küll valmis, aga liha oli nõder) algul inglise keelest vene keelde ja siis vene keelest tagasi inglise keelde, oli tulemuseks "The wine was excellent, but meat was rotten" (vein oli suurepärane, kuid liha oli halvaks läinud).
Vajadus masintõlke järele on suur, sellepärast on korduvalt algatatud suurte rahadega suuri projekte - ja siis praktiliste edusammude puudumise tõttu "rahad kinni keeratud ", nagu juhtus masintõlke esimese innustuse järel aastal 1966 peaaegu samal ajal nii USA-s kui ka Nõukogude Liidus. USA valitsus oli mures, sest raha läks masintõlke-alasele uurimistööle nagu kaevu, kuid tulemusi polnud; sellepärast organiseeriti Automatic Language Processing Advisory Committee (ALPAC), kes pidi masintõlke perspektiividest hinnangu andma. Komitee hinnangul on masintõlke kvaliteet kehv ja see on kaks korda kallim kui inimtõlkide kasutamine ja sellel pole perspektiivi. Sellega lõppes rahavoog; analoogilise otsuse tegi veidi hilem Nõukogude Liidu Teaduste Akadeemia. Kuid teistes maades (Kanadas, Saksamaal, Prantsusmaal) uurimine jätkus ja pisihilja tekkisid uuesti uurimisrühmad ka USA-s ja NL-s - alati leidub keegi, kes kinnitab, et nüüd ta teab, kuidas seda teha...
Masintõlge on seni edukas vaid väga kitsa sisuga tekstide puhul (näiteks Kanadas tõlgitakse edukalt ilmateated). Kuigi arvutid tõlgivad juba kümneid erialaseid ajakirju (matemaatika, füüsika jne - nendel aladel on sõnavara väiksem), on arvutiga saadud tulemus nn "toortõlge" - enamasti võimaldab aru saada, millest on jutt, kuid korraliku, "sileda" teksti saamiseks peab seda siluma inimene. Igaüks võib masintõlke kaasaja taset Internetis testida, seal on võimalik katsetada kõige tuntumaid masintõlkesüsteeme SYSTRAN, Babelfish jne. Näiteks Google-tõlkeleheküljel "http://www.google.com/language_tools" võib testida kahesuunalist tõlget umbes kümnesse keelde; Google ei täpsusta, milline programm seda teeb (esialgu kasutas Google SYSTRAN-i, kuid kuuldavasti tegeldakse ka Google-s masintõlkealgoritmidega). Järgnevas on samalt leheküljelt võetud (copy-paste) ingliskeelse lause edasi-tagasi tõlke tulemus, kui vahekeeleks olid saksa, prantsuse ja hispaania keel (mitte jaapani, hiina vms!):
Adjust the homepage Google, the announcements and the keys to announcement in your preselected language over our preference side.
Rules the homepage of Google, the messages and the keys to exposure in your language selected via our page of preferences.
Fix the homepage of Google, the messages, and the bellboys to the exhibition in its language selected via our page of the preferences.
Isegi teades, et need kolm lauset püüavad väljendada sama sisu (kõigil juhtudel oli ingliskeelne lähtelause sama) - mida siin kästakse/soovitatakse teha? Kuid Euroopa Liit kasutab SYSTRAN-programmi EU seaduste ja direktiivide tõlkimisel rahvuskeeltesse.
Paljud Tartu ülikoolis arvuti ja keele probleemidega alustanud uurijad jätkasid tööd Tallinnas Küberneetika Instituudis, kus 1968 a moodustati algoritmiliste keelte sektor (nimetati 1982 a ümber süsteemtarkvara sektoriks). 1960. a algul ilmunud programmeerimiskeele Algol eeskujul valmis Malle Kotlil 1966.a programmeerimiskeel MALGOL (Malle Algol), mida aastaid kasutati teadustöös ja programmeerimise õpetamiseks Tallinna Tehnoloogiaülikoolis (selle ajal TPI Tallinna polütehniline instituut); selleks kirjutati mitu MALGOL-keele õpevahendit. Peaaegu samal ajal valmis Vello Kuusikul analoogiline, aga vene kirjemärke (kirillitsat) kasutav keel VELGOL. Programmeerimiskeeli MALGOL ja VELGOL kasutati kogu Nõukogude Liidus ja mitmes teises sotsialistliku majandusühenduse maas (Ungaris, Tsehhis) ja need olid esimesi Nõukogude Liidus loodud programmeerimiskeeli; MALGOL ja VELGOL kuulusid ka Minskis toodetud M-seeria arvutite süsteemitarkvarasse.
MALGOL oli oma lihtsa süntaksiga programmeerimise õppimiseks väga sobiv keel; järgnevas on MALGOL-is kirjutatud programm integraali
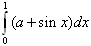
PROCEDURE' G(X,C) Y := A + SIN'X FOR' A := 0.1, 0.15, -10.3, -2 DO' BEGIN' INT := SIMPSON'(G(), 0,1,0.0005, 0.1, A) PRINT1'(A, INT) END'
Kuna keelte loomine oli saanud selgeks, loodi paljude eriotstarbeliste süsteemide jaoks oma sisend-väljundkeeled. Küberneetia Instituudis loodi 1965 a numbrilise kontrollisüsteemi keel SAP-2 ja 1983 - keel UTOPIST (B. Tamm, J. Pruuden, E. Pruuden). Kui Küberneetika Instituudis algasid Enn Tõugu juhtimisel tööd tehisintellektisüsteemide alal, loodi siin neile mitmeid sisendkeeli: PRIZ - 1983, NUT (New UTopist) - 1986. Ka üldotstarbeliste programmeerimiskeelte translaatorite alane töö jätkus, Vello Kuusiku juhtimisel valmis Moskava Juhtimissüsteemide Instituudi tellimusel mitu Ada keele alamhulki realiseerivat translaatorit.
Tallinna Tehnikaülikoolis (siis Tallinna Polütehniline Instituut, TPI) loodi 1980-ndate aastate algul Are Vooglaiu juhtimisel suur translaatorite genereerimise süsteem (compiler compiler) ELMA. Selle loomisel ja seda kasutasid keelte translaatorite genereerimisel paljud TPI arvutuskeskuse töötajad ja vastloodud majandusmatemaatika kateedri õppejõud: Marge Lepp, Viivi Jokk, Donald Liib, Hanno Rohtla jt. Kogu tegevust koordineeris Leo Võhandu, kes alati suutis leida lepinguid, mis tagasid tööst osavõtjatele tasu. Pärast Mati Tombaku ettekannet eelnevusgrammatikatest said eelnevusgrammatikad ELMA-s kasutatud süntaksianalüüsi meedodi aluseks. ELMA-e esitatavate leksika- ja süntaksikirjelduste formaliseerimiseks loodi keel ELMAMETA ja kogu translaatori genereerimise protsessi juhtimiseks - keel ELMAGUIDE. ELMA abil genereeriti kümneid keeli TPI informatsioonisüsteemile, ettevõtete majandusinfosüsteemidele jne. Kõige suurem ELMA abil realiseeritud projekt oli Ada-keele (täieliku) translaatori esimene pool: leksika- ja süntaksianalüsaator, mis tõlkisid Ada sisendi spetsiaalselt Ada transleerimiseks loodud vahekeelde Diana; silutud Ada süntaksigrammatika (eelnevusgrammatikana) kasutas 620 mitteterminali ja selles oli ca 750 produktsiooni. Ada translaator valmis Moskva Juhtimissüsteemide Instituudi tellimusel, kes pidi ise programmeerima (käsitsi) Ada translaatori tagumise otsa (Dianast koodi genereerimise), kuid nad ei suutnud projekti lõpetada. Sellel ajal oli kogu Nõukogude Liidus programmeerimise tase ja toodetud tarkvara kvaliteet äärmiselt madal; Tallinn oli üks neljast-viiest kohast kogu Nõukogude Liidus, kus osati programmeerida. Iseloomulik on näiteks fakt, et Kiievis nn "Gluskovi Instituudis" toodetavate arvutite "MIR" tarkvara oli niivõrd vigane, et regulaarselt igal aastal toimus üleliiduline konverents (mõnel aastal isegi kaks) arvuti "MIR" tarkvara-probleemide arutamiseks; ettekanded sellel konverentsil algasid sageli nii (tõlge mälu järgi):
"Tere, kallid seltsimehed! Meie arvuti "MIR" seerianumber on niisugune; kui konsoolil vajutada nii- ja niisuguseid klahve, siis peaks arvuti manuaali järgi juhtuma nii ja nii, aga tegelikult juhtub hoopis teisiti...", mille peale kohe hääl saalist hüüdis: "meie arvuti seerianumber on ühe võrra suurem (või väiksem)" (s.t. toodetud Kiievis kohe järgmisena või eelmisena) "ja kui meie vajutame samu klahve samas järjekorras, siis juhtub hoopis nõnna..." - s.t. iga arvuti oli unikaalne oma unikaalsete vigadega ja loomulikult oli sellistel arvutitel väga raske programmeerida ja peaaegu võimatu kusagil tehtud programme teises kohas kasutada. Kuid akadeemik Gluskovi poolt loodud arvutite ideed olid novaatorlikud, näiteks sai "MIR"-is programmeerija ise määrata arvutamistäpsuse, s.t. arvude salvestamisel kasutatava sõna pikkuse. Hiljem osutus, et ka siin oli väike probleem: kui TPI arvutuskeskuses Miša Mullat käivitas kord "MIR"-is õhtul mingi väga suure ülesande ja läks hommikul tulemusi saama, osutus, et mitte midagi pole - ta oli unustanud sõna pikkuse määrata ja "MIR" ei salvestanud mitte midagi. Kui Soome Helsingi Tehnikaülikool Otaniemes sai "MIR" arvuti (Nõukogude Liit püüdis sageli katta oma suurt kaubavahetusvõlga toodanguga, nn "oravanahaäri" soomlaste kõnepruugis), siis lammutasid nad selle kõigepealt osadeks ja panid siis uuesti hoolikalt kokku; ka kogu manuaal kirjutati uuesti, kõike hoolikalt kontrollides - see oli hiljem ka TPI-s ainuke arvuti "MIR" manuaal, milles ei olnud vigu.
Kui Mati Tombak siirdus TPI-st tööle Tartu Ülikooli, organiseeris ta kohe ka seal programmeerimiskeele Forth baasil translaatorite genereerimise süsteem; selle abil loodi mitmeid andme- ja infosüsteemide keeli, valmistati ühe Nõukogude Liidu Instituudi tellimusel tellija arvutile Forth-interpretaator jne.
 ©2004
Jaak Henno
©2004
Jaak Henno