Näide 1. Flex-i sisendprogramm translaatori genereerimiseks, mis leiab sisendtekstis kõik täisarvud ja lisab nende ette sõna Täisarv: .
%option noyywrap
NUMBER [0-9]
%%
{NUMBER}+ {printf( "Täisarv: %s\n", yytext );}
%%
main()
{
yylex();
}
Siin esimene rida %option noyywrap ütleb, et sisendfaili lõpuga lõpeb ka programmi flex.exe töö. Flex on koostatud järjest mitme sisendi käsitlemiseks, seega üksikute näidete tegemisel peab see rida alati olema. Rida NUMBER [0-9] defineerib lekseemi (token) NUMBER - see on ükskõik milline number 0..9; reegel {NUMBER}+ {printf( "Täisarv: %s\n", yytext )}; ütleb, et mingi numbrite jada leidmisel sisendist (Flex otsib alati maksimaalse reegli vasakule poolele vastava märgijada) tuleb väljastada ( C-keele printf-käsk) sõna "Täisarv: " ja selle järel see märgijada (stringina, muutuja yytext tüüp on string); figuursulud {..} piiravad nn semantilist tegevust, s.t. C-keele käske, mis tuleb sooritada, kui leitakse regulaarsele avaldisele NUMBER vastav tekstilõik; kui käske on vaid üks, võib figuursulud nende ümbert ära jätta (vt. järgmist näidet).
Salvestame selle teksti (näiteks) failis number.l (traditsiooniliselt on Flex-sisendfaili laiend .l - Flex-i eeskuju oli programm lex). Kuna Flex on DOS-programm, siis kõik edasine toimub DOS-aknas (või mõnes editoris, mis lubab sooritada DOS-käske, nagu näiteks KomodoEdit või Eclipse). Käsuga flex number.l (programmi flex.exe nime laiendi .exe võib ära jätta) genereeritakse sellest C-keelne programm lex.yy.c; loomulikult peab programm flex.exe olema leitav, s.t. süsteemimuutujas PATH on näidatud programmi flex.exe asukoht).
Kompileerime selle GNU C-translaatoriga gcc (ka gcc peab olema leitav!)
gcc lex.yy.c -onumber
Võtme (switch) -o järel on näidatud loodud translaatori nimi (ilma laiendita), s.t. translaator loob faili number.exe.Selle testimiseks loome näiteks testfaili test.txt:
Numbrid 2 3 4
ja 505.
Käivitame nüüd loodud translaatori, andes sellel sisendiks (DOS-suunaja < abil) faili test.txt ja saadame tulemuse (suunaja > abil) faili tulemus.txt (ka translaatori number.exe nime järel võib laiendi .exe ära jätta):
number < test.txt > tulemus.txt
Faili tulemus.txt sisu tuleb selline: Numbrid: Täisarv: 2
Täisarv: 3
Täisarv: 4
ja Täisarv: 505
.
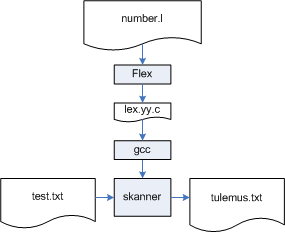
Nagu näha, transaator on teisendanud sisendi test.txt korrektselt - täisarvude ette trükiti sõna "Täisarv ", ülejäänud tekst ei muutunud.
Täpselt sama lõpptulemuse saame kui Flex-i sisendfailis
muudame lekseemi definitsiooni nii, et kogu sisendist leitud numbrite
jada oleks lekseem, s.t. esitada see kujul ARV  [0-9]+;
sel juhul loomulikult peab ka reeglit muutma, eemaldades sealt
iteratsiooni; kui lisaks sellele tahetakse, et saadud lekser eemaldaks
sisendist (peale täisarvude) kõik muud sümbolid,
lisame arvude käsitlemise reegli järele reegli, mille vasakul
pool olev sümbol . (punkt)
vastab kõigile sisendteksti sümbolitele, v.a. reavahetus;
reegli parem pool on tühi, s.t. punktile vastavate sümbolite
leidmisel pole vaja teha midagi; kuna Flex käsitleb reegleid
selles järjekorras, milles nad on antud, on tekstis esinevad
täisarvud eelmise reegliga juba käsitletud (mis juhtub, kui
need reeglid anda vastupidises järjekorras?), seega uus number.l oleks
[0-9]+;
sel juhul loomulikult peab ka reeglit muutma, eemaldades sealt
iteratsiooni; kui lisaks sellele tahetakse, et saadud lekser eemaldaks
sisendist (peale täisarvude) kõik muud sümbolid,
lisame arvude käsitlemise reegli järele reegli, mille vasakul
pool olev sümbol . (punkt)
vastab kõigile sisendteksti sümbolitele, v.a. reavahetus;
reegli parem pool on tühi, s.t. punktile vastavate sümbolite
leidmisel pole vaja teha midagi; kuna Flex käsitleb reegleid
selles järjekorras, milles nad on antud, on tekstis esinevad
täisarvud eelmise reegliga juba käsitletud (mis juhtub, kui
need reeglid anda vastupidises järjekorras?), seega uus number.l oleks
%option noyywrap
ARV [0-9]+
%%
{ARV} printf( "Täisarv: %s\n", yytext );
. /* tühja parema poolega reegel "neelab alla" kõik
ülejäänud märgid */
%%
main()
{
yylex();
}
Täisarv: 2
Täisarv: 3
Täisarv: 4
Täisarv: 505
Kui asendada väljundit moodustav rida reaga
{ARV} printf("<int> %s</int>", yytext);
moodustatakse sisendis täisarvude ümber XML-märgendid (tag) <int>...</int>. Nii on lihtne teisendada kogu sisend XML-märgendatud tekstiks, nii et järgnevad teisendused võib teha (näiteks) XSL-interpretaatoriga.Näide 2. Järgneva sisendiga moodustatakse skanner, mis loeb kokku sisendteksti read ja sümbolid:
%option noyywrap
%{
int num_lines = 0, num_chars = 0;
%}
%%
\n ++num_lines; ++num_chars; /* reavahetus suurendab nii ridade kui ka
loetud märkide arvu */
. ++num_chars; /* suureneb vaid loetud märkide arv */
%%
main()
{
yylex(); printf(
"Ridu: %d, Symboleid (char): %d\n", num_lines, num_chars ); }
Näide 3. Järgnev Flexi sisend genereerib programmi, mis muudab tekstis esinevate sõnade esitähed suurtähtedeks (Microsoft Word-is nimetatakse seda funktsiooni "Title Case"); esimene reegel on tühiku järel oleva väiketähe jaoks ja teine - rea algul oleva väiketähe jaoks (seda juhtu esimene reegel ei kata):
%option noyywrap
TYHIK [ \t]
VAIKETAHT [a-z]
%%
{TYHIK}{VAIKETAHT} { yytext[yyleng-1]+='A'-'a';
printf( "%s", yytext ); }
/* 'A'-'a' on ASCII tabelis suurtähtede ja väiketähtede
koodide vahe */
/* selle liitmisel koodile muutub väiketäht suurtäheks */
^{VAIKETAHT} { yytext[yyleng-1]+='A'-'a'; printf( "%s", yytext ); /*
väiketäht rea algul! */}
%%
main()
{
yylex();
}
Näide 4. Täiendame ülalesitatud täisarvude leidmise programmi nii, et see leiaks ka reaalarvud ja arvu ees võiks olla ka märk. Programm "neelab alla" (läheb yle) tühikutest (" ", tabuleerimis- või reavahetusmärk), kõigi tesite sümbolite leidmisel aga annab vea:
%option noyywrap
NUMBER [0-9]
MARK (\+|\-)?
TARV {MARK}{NUMBER}+
RARV {TARV}\.{NUMBER}*|{MARK}\.{NUMBER}*
TYHIK [ \n\t]+
%%
{RARV} {printf("Real: %s\n", yytext );}
{TARV} {printf("Integer: %s\n", yytext);}
{TYHIK} /*ei tee midagi */
. {printf("Viga: %s\n",yytext);}
%%
main()
{
yylex();
}
Siin reaalarvu leidmise reeglis {RARV} on kirjeldatud ka reaalarvud, kus pärast punkti võibolla ei ole enam numbereid (esimene alternatiiv) või kus enne punkti ei ole numbreid (teine alternatiiv).
Näide 5. Järgnevas on Flex-i sisendtekst Pisi-Algoli
lekseemide tunnistamiseks. Siin on oluline (teises osas, kus
kirjeldatakse semantilisi tegevusi) reeglite järjekord:
võtmesõna reegel peab kindlasti olema enne
identifikaatori reeglit, muidu loetakse kõik tähega algavad
tähtede-numbrite jadad identifikaatoriteks. See programm ainult
leiab sisendteksti lekseemid ja väljastab vastava teksti; leitud
arvud muudetakse C-keele funktsiooni atoi
abil arvudeks ja väljastatakse arvudena (mitte stringidena);
funktsiooni atoi kasutamiseks
peab programmi algul lisama ka teegi math.h.
Kuna tühikud ja
reavahetused on vajalikud vaid lekseemide eraldamiseks üksteisest,
võib nad pärast lekseemide leidmist eemaldada, sest
edasises pole neid enam vaja (operatsioonimärke, omistusmärki
:=, käsu
lõpusümbolit ; jne on
järgnevas süntaksianalüüsis käskude struktuuri
leidmiseks tarvis!). Tühikuteks on "päris" tühik ' ', tabulatsioonimärk
\t , carriage-return \r ja line-feed \n (Unix-is kasutatakse \n,
Macintoshis \r ja Windows-is - \r\n, neid tähistatakse ka CR, LF).
%option noyywrap
%{
/* järgnev on vajalik tüübiteisendusfunktsiooni atoi()
saamiseks */
#include <math.h>
%}
VOTMESONA IF|THEN|ENDIF|FOR|UNTIL|DO|ENDLOOP|READ|PRINT
TAHT [A-Z]
NUMBER [0-9]
IDENTIFIKAATOR {TAHT}({TAHT}|{NUMBER})*
ARV {NUMBER}+
TYHIKUD [ \t\r\n]+
OMIST ":="
ERALDAJA "+"|"-"|"*"|"/"|"<"|">"|"="|";"
%%
{VOTMESONA} printf( "Votmesona(%s) ", yytext );
{IDENTIFIKAATOR} printf( "Identifikaator(%s) ", yytext );
{ARV} printf( "Arv(%d) ", atoi(yytext) );
{ERALDAJA} printf( "Eraldaja(%s) ", yytext );
{OMIST} printf( "Omistamine(%s) ",yytext);
{TYHIKUD} { /* tühikud ja reavahetused "neelatakse alla" s.t.
kustutatakse */};
. { printf( "Viga -(%s)\n",%s );/* exit( 0 ); */ }
%%
main()
{
yylex();
}
Eespool esitatud Pisi-Algol-is kirjutatud näidisprogrammi Fibbonacci
arvude leidmiseks
READ N;
F0 := 0;
F1 := 1;
FOR I := 2 UNTIL N DO
F2 := F0 + F1;
F0 := F1;
F1 := F2;
ENDLOOP;
PRINT F2;
Votmesona(READ) Identifikaator(N) Eraldaja(;) Identifikaator(F0) Omistamine(:=) Arv(0) Eraldaja(;) Identifikaator(F1) Omistamine(:=) Arv(1) Eraldaja(;) Votmesona(FOR) Identifikaator(I) Omistamine(:=) Arv(2) Votmesona(UNTIL) Identifikaator(N) Votmesona(DO) Identifikaator(F2) Omistamine(:=) Identifikaator(F0) Eraldaja(+) Identifikaator(F1) Eraldaja(;) Identifikaator(F0) Omistamine(:=) Identifikaator(F1) Eraldaja(;) Identifikaator(F1) Omistamine(:=) Identifikaator(F2) Eraldaja(;) Votmesona(ENDLOOP) Eraldaja(;) Votmesona(PRINT) Identifikaator(F2) Eraldaja(;)
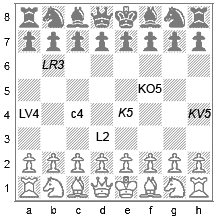 Maleraua
ruutude tähistamiseks kasutatakse kaasajal geomeetrilist
koordinaatsüsteemi, milles veerud on tähistatud tähtedega a,b,c,d,e,f,g,h ja read numbritega 1,2,3,4,5,6,7,8 (numeratsioon algab
valge poolt). Vanemas malekirjanduses võib kohata ka vanemat, malendite
algseisul põhinevat süsteemi, milles veerud tähistatakse lv (Lipu Vanker), lr (Lipu Ratsu), lo (Lipu Oda), l (Lipp), k(Kuningas),
ko (Kuninga Oda), kr (Kuninga Ratsu) ja kv (Kuninga Vanker); read tähistatakse
numbritega 1,2,3,4,5,6,7,8 kuid
rea numbrid algavad mõlema maletaja jaoks tema malendite algsesisust,
s.t. valge tähistuses ruut kv4 on
musta jaoks kv5 ja valge
tähistuses ruut ko5 on mustal ko4 (kõrvaloleval pildil on musta
tähistused kaldkirjas). Partii kirjeldatakse käikude järjestusena, kus
käik algab järjekorranumbriga, seejärel on valge käik (valge tähistusi
kasutades) ja siis musta käik (musta tähistusi kasutades). Käigu
kirjeldus algab malendi esitähega: L, K,
O, R, V (etturi jaoks tähistust ei kasutata) ja seejärel on käik
formaadis lähteruut - lõppruut ,
seega näiteks kaasaegses tähistuses partii algus
Maleraua
ruutude tähistamiseks kasutatakse kaasajal geomeetrilist
koordinaatsüsteemi, milles veerud on tähistatud tähtedega a,b,c,d,e,f,g,h ja read numbritega 1,2,3,4,5,6,7,8 (numeratsioon algab
valge poolt). Vanemas malekirjanduses võib kohata ka vanemat, malendite
algseisul põhinevat süsteemi, milles veerud tähistatakse lv (Lipu Vanker), lr (Lipu Ratsu), lo (Lipu Oda), l (Lipp), k(Kuningas),
ko (Kuninga Oda), kr (Kuninga Ratsu) ja kv (Kuninga Vanker); read tähistatakse
numbritega 1,2,3,4,5,6,7,8 kuid
rea numbrid algavad mõlema maletaja jaoks tema malendite algsesisust,
s.t. valge tähistuses ruut kv4 on
musta jaoks kv5 ja valge
tähistuses ruut ko5 on mustal ko4 (kõrvaloleval pildil on musta
tähistused kaldkirjas). Partii kirjeldatakse käikude järjestusena, kus
käik algab järjekorranumbriga, seejärel on valge käik (valge tähistusi
kasutades) ja siis musta käik (musta tähistusi kasutades). Käigu
kirjeldus algab malendi esitähega: L, K,
O, R, V (etturi jaoks tähistust ei kasutata) ja seejärel on käik
formaadis lähteruut - lõppruut ,
seega näiteks kaasaegses tähistuses partii algus
1 e2 - e4 e7 - e5
2 Of1 - b5 c7 - c6
1 K2 - K4 K2 - K4
2 Oko1 - lr5 lo2 - lo3
Esmaspäev, 16.00, Translaatorite koostamine
Esmaspäev, 17.30, Translaatorite koostamine
Kolmapäev, 14.00, Mängude programmeerimine
Programm peab kontrollima, et kõik read on sellises formaadis; päev peab olema Esmaspäev .. Reede, kellaajas tund peab olema paaristund 08 .. 18, minutid: 00 või 30.
a op b a b op
op + | - | * | /
23 üks 34 kaks
väljund võiks olla näiteks sellinerida 1 1-2: 23, 4-6: üks rida 2 2-3: 34 5-8: kaks
Koosta Flex-programm (skanner) Haskell-i nimede tunnistamiseks; skanner peab teatama iga sisendis esitatud nime jaoks, kas see on korrektselt kirjutatud või ei ja kumba tüüpi see on; nimed on üksteisest eraldatud kas tühikute, tabulatsioonisümbolite, komade või reavahetustega; programm (skanner) peab kogu sisendi lõpuni läbi vaatama (mitte peatuma esimese vea korral).
varsym (symbol
{symbol | : } )<reservedop | dashes >
consym (: {symbol | : } ) <reservedop>
reservedop .. | : | :: | = | \ | '|' |
<- | -> | @ | ~ | =>
symbol ! | # | $ | % | & | * | + | . |
/ | < | = | > | ? | @ | \ |ˆ | '|' | - | ~
dashes --{-}
Ülalesitatud produktsioonides metasümbolid { } tähistavad nende vahel oleva osa kordust 0,1,2... korda ja tähistus (reg_avald1)<reg_avald2> märgib kõikki reg_avald1 poolt kirjeldatud märgijadasid, v.a. need, mida kirjeldab reg_avald2 (s.t. hulga {reg_avald2} täiend hulga {reg_avald1} suhtes).
Koosta Flex-programm Haskell-i formaalsete argumentide kontrolliks: genereeritud skanner peab iga sisendfailis esitatud formaalse parameetri kohta teatama, kas see on korrektselt kirjutatud ja kumba liiki see on; skanner peab kogu sisendi lõpuni läbi vaatama (mitte peatuma vea korral); formaalsete argumentide eraldajad sisendfailis on tühikud, tabulatsioon, komad või reavahetused.
///////////////////////////////////////////////////////Koosta selle näite põhjal Flex-programm Swi-Prolog-i programmi tekstis siin kirjeldatud lekseemide Identifier NumConst EscapeChar KeyWords1 KeyWords2 KeyWords3 leidmiseks (kui oskate, ka värvimiseks).
// SWI Prolog highlighter written by Pascal Snijders Blok, ppsnijde@cs.vu.nl
//
//////////////////////////////////////////////////////////////////////////////
Language: SWI Prolog
Filter: SWI Prolog files (*.swi)|*.swi|*.pl
HelpFile: "Swi-Prolog.hlp"
CaseSensitive: 1
LineComment: %
BlockCommentBeg: /*
BlockCommentEnd: */
IdentifierBegChars: a..z A..Z
IdentifierChars: a..z A..Z 0..9 _
NumConstBegChars: 0..9
NumConstChars: 0..9
EscapeChar: \
KeyWords1: abolish abs absolute_file_name access_file acos
append apply apropos arg arithmetic_function asin assert asserta
write write_canonical writef write_ln writeq write_term abort break halt trace prolog make
KeyWords2: not is mod xor
KeyWords3: e pi cputime
 ©2004-2013 Jaak Henno
©2004-2013 Jaak Henno