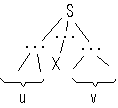 Ülalt-alla analüüsis
ainuke situatsioon, kus midagi võib minna valesti (s.t. hiljem võib
tekkida vajadus tagurdamiseks), on situatsioon, kus arendava
mitteterminali (s.t. "pooliku" derivatsioonipuu esimese "rippuva"
mitteterminali) jaoks on olemas mitu produktsiooni, kus see
mitteterminal on vasakul, näiteks X
Ülalt-alla analüüsis
ainuke situatsioon, kus midagi võib minna valesti (s.t. hiljem võib
tekkida vajadus tagurdamiseks), on situatsioon, kus arendava
mitteterminali (s.t. "pooliku" derivatsioonipuu esimese "rippuva"
mitteterminali) jaoks on olemas mitu produktsiooni, kus see
mitteterminal on vasakul, näiteks X  v | v'
v | v'
Sellisel juhul on loomulik proovida mitteterminali arendamiseks kasutatav produktsioon valida analüüsitava terminalidest koosneva stringi k-tähelist algusosa kasutades.
Olgu x mingi terminalidest ja
mitteterminalidest koosnev string; funktsiooni FIRSTk(x) väärtuseks on
kõigi x-st tuletatavate
terminalidest koosnevate stringide k-täheliste algusosade hulk. Kuna
tavaliselt x on mingi
produktsiooni X x parem pool, kasutatakse FIRSTk(x) asemel sageli
tähistust FIRSTk(X x ), kuid selline tähistus määrab juba
ka stringi x konteksti - x saadakse mitteterminali X asendamisel, s.t. selle kontekst on X kontekst; kuna x võib tekkida ka mõnel teisel viisil
(mitte asendusest X x), võib hulk FIRSTk(X x ) olla väiksem kui hulk FIRSTk(x).
Kui x-st saab ka sõnu, mille pikkus on < k (näiteks kui x 
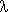 ), on tarvis FIRSTk(x) arvutamiseks teada
ka X-i parempoolset konteksti (s.t. sümboleid, mis võivad X-le järgneda. k-tähelisi x-le
järgnevate stringide hulka tähistatakse FOLLOW
k(x) ja see kontekst lisatakse siis funktsiooni FIRST esimesele argumendile, aga teise
argumendina näidatakse X
arendamiseks kasutatav produktsioon (vt näide 2. allpool).
), on tarvis FIRSTk(x) arvutamiseks teada
ka X-i parempoolset konteksti (s.t. sümboleid, mis võivad X-le järgneda. k-tähelisi x-le
järgnevate stringide hulka tähistatakse FOLLOW
k(x) ja see kontekst lisatakse siis funktsiooni FIRST esimesele argumendile, aga teise
argumendina näidatakse X
arendamiseks kasutatav produktsioon (vt näide 2. allpool).
Kontekstivaba grammatikat nimetatakse LL(k) grammatikaks, kui iga kahe derivatsiooni
S uXw uvw
S uXw
uv'w
Kõige sagedamini kasutatakse LL(1) grammatikaid, sest nende kasutamisel on analüüs kõige kiirem (tarvis on analüüsitavas stringis ette vaadata vaid üht sümbolit).
Kui grammatikas ei ole tühja parema poolega produktsioone (s.t. pole
produktsioone kujul X ), võib LL(1) tingimuse esitada palju lihtsamal
kujul: grammatika on LL(1), kui
kõigi sama vasema poolega produktsioonide
X w1 | w2
| ... | wn
 FIRST1(wi)
=
FIRST1(wi)
= 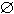 (
i
(
i  j ).
j ).
Grammatikat nimetatakse lihtsaks LL(1) grammatikaks, kui selles ei ole
tühja parema poolega reegleid X ja kõigi
sama vasaku poolega reeglite X w1 | w2 | ... | wn
korral see tingimus on täidetud, s.t. kõik alternatiivid w1, w2, ... , wn
algavad erinevate terminalidega.
Näide 1. Grammatika
S aXS | b
X a | bSX
Näide 2. Vaatleme grammatikat
S | abA
A Saa | b
Kuna mitteterminalist S võib
saada tühja sõna , on FIRSTk(S) leidmiseks tarvis
analüüsida mitterminali S kõiki
parempoolseid kontekste, s.t. stringe, mis võivad tekkida S järel (hulk FOLLOWk(S) ); kuna see hulk
sõltub sellest, mis tuleb S järel
(S-i parempoolsest kontekstist),
uurime eraldi iga juhtu, kus S
tekib (s.t. kõiki reeglite paremaid pooli, kus S esineb) ja lisame funktsiooni FIRST teiseks argumendiks
mitteterminali arendamiseks kasutatud reegli parema poole:
FIRST1(Sa, ) = {a}, FIRST1(Sa, abA) = {a}
Kuna saime samad hulgad, ei ole see grammatika LL(1) grammatika, sest ühe sümboli ette
vaatamisega ei ole võimalik otsustada, kas mitteterminal S kontekstis Sa tuleb arendada tühjaks sõnaks või stringiks abA
.
Vaatleme kaheelemendilisi alglõike:
FIRST2(Saa, ) = {aa}, FIRST1(Saa, abA) = {ab}
Kuna kaheelemendilised alglõigud on erinevad, on see LL(2) grammatika - kahe sümboli ette vaatamisega saab alati otsustada, milleks S tuleb arendada.
Näide 3. Uurime grammatikat
S A | B
A aAb | 0
B aBbb | 1
Lihtne on näha, et L(S) = {an0bn
}  {an1b2n },
n=0,1,2,...
{an1b2n },
n=0,1,2,...
See tähendab, et see grammatika ei ole LL(k) -grammatika ühegi k korral, sest lõpliku (fikseeritud)
pikkusega stringi vaatamisega ei ole võimalik otsustada, kas esimesel
sammul kasutada produktsiooni S A või
S B; seda saab teha alles siis,
kui a-de jada järel loetakse 0 või 1,
kuid a-de jada võib olla kuitahes
pikk, s.t. see (esimesel sammul produktsiooni valikut määrav kontekst)
võin olla kuitahes kaugel.
Näide 4 . Grammatika
S aS | aB
B
bB | b
L(S) = {anbm, n,m  N
},
N
},
S aS | abB
B
bB | b
Näide 5 . Grammatika
S aS | SB
B
bB | b
L(S) = {anbm, n,m N
},
S aS | abB
B
bB | b
On lihtne näha, et LL(k) grammatika puhul saab ülalt-alla analüüsi teha lineaarse kiirusega (analüüsitava stringi pikkuse suhtes).
S aAaa | bAba
A b |
S aAaB | bAaB
A a | ab
B bB | bb
S Sa | b
S bA
A aA |
S A B C
A A a | b B
B B b |
C C c |
1) a ![]() FIRST1(S); 2) c
FIRST1(S); 2) c ![]() FIRST1(Aa);
3) c
FIRST1(Aa);
3) c ![]() FOLLOW1( A); 4) - see on kas LL(1) või LL(2)
grammatika.
FOLLOW1( A); 4) - see on kas LL(1) või LL(2)
grammatika.
S aS | a
S aA
A S |
S aaSbb | a |
X... )
võib olla LL(k) grammatika
(ükskõik millise k korral, v.t.
ülesanne 3) ? A aBC
B c | cd
C df | eg
L = {anb2n } {a2nbn }, n=0,1,2,...
Koosta LL(1) või LL(2) grammatika numbrilise suuruse kirjeldamiseks.
Statement
CompoundStatement | Assignment | ProcedureCall
| IfStatement | WhileStatement
| WriteStatement | ReadStatement ProcedureCall ProcIdentifier
ProcIdentifier Identifier
Assighnment Identifier := Expression
See grammatika ei ole LL(1) - miks? Kas see grammatika on LL(2) ? Teisenda grammatika LL(1) -grammatikaks!
Program
Declarations Function_declarations
Declarations Declaration
Feclarations
| Declaration Type Identifier-list;
Identifier_list Identifier
| Identifier-list , Indentifier Identifier
ident
| * Identifier Type int
| float
| char
| void Function_declarations Function_declaration Function_declarations
| Function_declaration Function_head Function_body
Function_head Type Identifier
Arguments
Arguments ( Parameter_list )
| ( ) Parameter_list Parameter Parameter_list
| Parameter Type Identifier
Siin kirjeldamata mitteterminalid (ident, function_body) võib lugeda terminalideks; terminalid on ka kõik kirjelduses esinevad sulud ( ) .
See grammatika ei ole LL(1) - miks? Milline on minimaalne k, mille jaoks see grammatika oleks LL(k) grammatika?
 ©2004-2013 Jaak Henno
©2004-2013 Jaak Henno