Teoreetilises kirjandudses kasutatakse grammatikate esitamisel tavaliselt samasugust (kõige lihtsamat) tähistusviisi nagu siin seni on kasutatud - produktsiooni parema ja vasaku poole vahel on eraldajaks nool, mitteterminalidele mingeid erimärgendedi ei kasutata ja terminalid (s.t. lõplikus, grammatika poolt genereeritud tekstis esinevad sümbolid (characters - märgid) võetakse kas apostroofide või jutumärkide vahele, seega näiteks täisarvu (mittetühi numbrite jada) kirjeldatakse produktsioonidega:
number  '0'
'0'
number '1'
number '2'
number '3'
number '4'
number '5'
number '6'
number '7'
number '8'
number '9'
täisarv number
number täisarv number
Programmikonstruktsioonide kirjeldamiseks kasutatakse produktsioonide asemel ka teistsuguseid formalisme. Pascal-i looja Niclaus Wirth võttis kasutusele nn laiendatud BNF formalismi (EBNF - Extended Bacus-Naur Formulas), kus reegli parema pool võib kasutada regulaarsetes avaldistes kasutatavaid metasümboleid.
Metasümboliga [ ] ümbritsetakse võimalik element - kandilistesse sulgudesse võetud osa võib olla, aga võib ka puududa, s.t. esineb kas 0 või 1 korda (kasutatakse ka tähistust ( )? ), näiteks reeglite
märgiga_arv arv
märgiga_arv märk arv
[märk] arv või
arv (märk)?
täisarv
Iteratsioonisümboleid * (kordus 0,1,2,... korda) ja + (kordus 1,2,... korda) ning valikusümbol | võimaldavad eespoolesitatud täisarvu kirjelduse esitada palju lühemalt:
number '0' | '1' | '2'
| '3' | '4' | '5' | '6' | '7' | '8' | '9' |
täisarv number +
Ka identifikaatori kirjelduse
ident täht
ident ident täht
ident ident number
võib nüüd esitada ühe reeglina ident täht
(täht | number)*. Iteratsiooni tähistamiseks
kasutatakse sulgude ja nende järel tärni asemel
mõnikord ka figuursulge, s.t. eelneva reegli kirjaviis
võib olla ka selline: ident täht {täht | number}
Metasümbolite kasutamisel peab arvestama, et need sümbolid võivad esineda ka defineeritavas keeles, s.t. näiteks [ ] on paljudes programmeerimiskeeltes vektori (array) indeksi eraldajad, s.t. grammatika terminalid. Terminalina (mitte metasümbolina) kasutamisel võetakse sümbol jutumärkide või apostroofide vahele; mõnes süsteemis (näit Antlr) peab kõik terminalid esitama apostroofide vahel, mõnes (Flex) aga ainult need, mida kasutatakse ka metasümbolitena. Metasümbolina (tähistuste rühmitamiseks) kasutatakse sageli ka sulge ( ) .
Translaatorites kasutavad grammatikad on kõik kirjeldatud arvutis ja arvutis vastab igale tähele numbriline kood (nn ASCII kood). Neid koode, s.t. nende koodide põhjal defineeritud järjestust kasutatakse märkide vahemike kirjeldamiseks, kuid erinevates süsteemides kasutatakse veidi erinevaid tähistusi. Näiteks eespoolesitatud numbri produktsioon kirjeldatakse leksiliste analüsaatorite genereerimise programmis Flex kujul:
NUMBER [0..9]
s.t. noole asemel on tühikud, mitteterminalid kirjutatakse suurte tähtedega ja [0..9] tähistab märkide vahemikku 0|1|@|3|4|5|6|7|8|9. Translaatorite genereerimise süsteemis Antlr kasutatakse veidi erinevat tähistust:
NUMBER : '0'..'9' ;
Esimese programmeerimiskeele Fortrani grammatika kirjuutamisel
kasutas John Backus veidi keerukamat formalismi: noole asemel oli konstruktsioon ::= ja mitteterminalid võeti
teravate nurksulgude < >
vahele, seega selles kirjaviisis oleks täisarvu kirjeldus selline:
<number> '0'
<number> '1'
<number> '2'
<number> '3'
<number> '4'
<number> '5
<number> '6'
<number> '7'
<number> '8'
<number> '9'
<täisarv> <number>
<täisarv> <number><täisarv>
Kaasajal on nurksulgude kasutamisest mitteterminalide tähistamiseks enamasti loobutud, kuid neid võib kohata teistsugustes tähistustes, näiteks programmeerimiskeeles Dylan kasutatakse neid sisseehitatud andmetüüpide tähistamisel.
Pascali süntaksi esitamiseks leiutas selle auto Niclas Wirth veel ühe formalismi süntaksi kirjeldamiseks: süntaksiskeemid.
 Näiteks täisarvu produktsiooni täisarv number |
täisarv number võib kirjeldada kõrvaloleva skeemiga:
Näiteks täisarvu produktsiooni täisarv number |
täisarv number võib kirjeldada kõrvaloleva skeemiga:
Eespoolvaadeldud mitteterminali ident struktuuri võib kirjeldada järgmise skeemiga:

Pascal-i defineerimisel kasutatud produktsioonid märgita arvu (täisarv, reaalarv, järguga arv) defineerimiseks:
märgita_täisarv number | märgita_täisarv number
[järguosa]
järguosa E [ + | - ]
märgita_täisarv

Kuna formaalseig grammatikaid peab sageli lugema ka arvuti, on grammatikate tähistusviisi püütud standardiseerida. ISO/IEC 14977 standardiseerib EBNF (Extended Bacus-Naur Formulas), lihtsustades veidi Backus-Nauri tähistusi ja lisades Wirth-i poolt kasutusele võetud regulaarsete avaldiste sümbolitele veel mõned. Selle peamised jooned on:
)ISO standardeid ei ole võimalik uurida WWW-s, nendega tutvumiseks peab standardi ISO-lt ostma. See raskendab ISO standardite levikut, sest programmeerija sageli realiseerib mingi standardiga kirjeldadud formaadi "umbes nii nagu kõik teevad", standardi ostmine ja uurimine näib liiga tülikana. Praktikas ei ole see standard eriti levinud, sest see erineb (näit koma kasutamine) tunduvalt tavalisest kirjaviisist. Näiteks programmeerimiskeeles Fortran 77 on reegel, et kui rea algul on viis tühikut, siis tuleb mingi märk, mis ei ole tühik ega null ja seejärel tuleb veel mitte rohkem kui 66 märki (seega rea pikkus on < 72 = 5+1+66), siis see programmikäsk jätkub järgmisel real; ISO standardi järgi peaks selle kirja panema nii:
Fortran 77 continuation line = 5 * " ",(character - (" " | "0")), 66 * [character] ;
Oma formaati grammatikate kirjapanekuks soovitab WWW- leiutaja Tim Berners-Lee poolt juhitav WWW-d reguleeriv organisatsioon W3W. W3W soovitustes (W3W recommendation - neid peetakse standarditega samaväärseteks) kasutakse Backus-Nauri ja Flex-Yacc-i tähistuste ristsugutist. Järgnevad reeglid on võetud XML-märgendkeele 2004 aasta soovitusest http://www.w3.org/TR/REC-xml/).
Produktsioonid esitatakse kujul
Mitteterminal avaldis
Paremal pool olevas avaldises võib kasutada järgnevaid lühendeid:
#xN -
heksadetsimaalarv, mille kood N
on esitatud standardis ISO/IEC 10646 kohaselt;
[a-zA-Z], [#xN-#xN] - märkide
vahemikud (nagu Flex-is); nagu kõigis grammatikaformalismides,
ei pea sama mitteterminali erinevad esinemised reegli paremal pool
tähistama sama stringi, s.t. koodi N
väärtused avaldises [#xN-#xN]
on erinevad (muidu poleks kogu avaldisel mõtet);
[abc], [#xN#xN#xN] -
ükskõik milline nendest märkidest (valik - nagu
Flex-is); loomulikult on ka siin on N
väärtused erinevad;
[^a-z], [^#xN-#xN] - iga (lubatud)
märk, mis ei kuulu nendesse vahemikkudesse (täiend - nagu
Flex-is); et täiendit saaks kasutada, peab enne olema
määratud kõigi lekstis lubatud märkide hulk,
näiteks märgendkeele XML kirjelduse algab produktsiooniga,
mis määrab kõigi tekstis esineda võivate
märkide Unicode-koodid:
Char #x9 | #xA | #xD | [#x20-#xD7FF] |
[#xE000-#xFFFD] | [#x10000-#x10FFFF]
Täiendi kasutamisel võib kergesti tekkida raskestiavastatavaid vigu, sellepärast peab enne täiendi kasutamist kindlasti olema määratud, millise märkide hulga suhtes täiendit kasutatakse. Paljudes programmeerimiskeeltes määratakse näiteks mõiste "string" järgmise reegliga: string on kas jutumärkide " ..." või apostroofide '...' vahel olev märgijada, milles ei esine selle stringi eraldaja (vastavalt kas " või '). Ülalkirjeldatud XML-märgendkeele soovituses/standardi kohaselt esitatakse see reegel täiendi abil järgmiselt:
SystemLiteral ('"' [^"]* '"') | ("'" [^']* "'")
See definitsioon oleks üksi tegelikult vigane - see ei välista, et näiteks jutumärkide "..." vahel ei võiks olla paaritu arv apostroofe '...'...', kuid XML-keele kirjelduse muud reeglid välistavad kahemõttelisused.
Täiendi kasutamine võib ka muuta reegli raskesti arusaadavaks. XML-dokumendis kommentar on märgend kujul <!-- Kommentaaari tekst -->, kus kommentaari tekstis ei või esineda järjest kaks miinust, s.t. märgid -- . XML keele kirjelduses on kommentaari süntaks kirjeldatud produktsiooniga
Comment '<!--' ((Char - '-') | ('-' (Char - '-')))* '-->'
s.t. kommentaari tekstis võivad esineda mistahes märgid v.a. miinus (esimene alternatiiv) või miinus, kuid sellele järgnev märk ei või olla miinus (teine alternatiiv). Kuid selle definitsiooni järgi miinus ei või olla kommentaari viimane märk (sellele peab tingimata järgnema veel mingi mitte-miinus märk), s.t. kui (poolkogemata) on kirjutatud <!-- -Kommentaaari tekst --->, siis selline kommentaar (ja seega kogu XML-dokument) on vigane; kommentaar on korrektne, kui esimese miinuse järel on (näiteks) tühik, st. kommentaar on kujul
<!-- -Kommentaaari tekst - -->
.

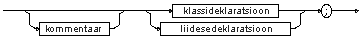
floatnumber
pointfloat | exponentfloat
pointfloat
[intpart] fraction | intpart "."
exponentfloat
(intpart | pointfloat)
exponent
intpart
digit+
fraction
"." digit+
exponent
("e" | "E") ["+" | "-"] digit+
digit [0..9]
number: 123, 1.5, -4.0, #x1f4e
character: 'a', '\n'
string: "appi", "line 1\nline 2"
symbol: test:, #"red"
tõeväärtused (boolean value): #t, #f
paar: #(1 . "one")
nimistu (list): #(1, 2, 3)
vektor (vector): #[1, 2, 3]
Koosta nende näidete põhjal Dylani objektitähistusi kirjeldav grammatika.
‹sign> ::= “+” | “-”
‹digit> ::= “0” | “1” | “2” | “3” | “4” | “5” | “6” | “7” | “8” | “9”
‹digits> ::= ‹digit>‹digits> | ‹digit>
‹factor> ::= ‹digits>
‹exponent> ::= ‹sign>‹digits> | ‹digits>
‹simple-unit> ::= ‹ATOM-SYMBOL>
| ‹PREFIX-SYMBOL>‹ATOM-SYMBOL>
‹annotatable> ::= ‹simple-unit>‹exponent>
| ‹simple-unit>
‹component> ::= ‹annotatable>‹annotation>
| ‹annotatable>
| ‹annotation>
| ‹factor>
| “(”‹term>“)”
‹term> ::= “/”‹component>
| ‹component>“.”‹term>
| ‹component>“/”‹term>
| ‹component>
‹annotation> ::= “{”‹ANNOTATION-STRING>“}”
ja selle abil kodeeritud mõõtühikuid tunnistav automaat: 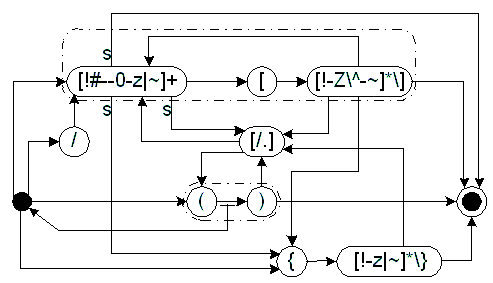
 ©2004
Jaak Henno
©2004
Jaak Henno