JFLAP - abivahend lõplike automaatide, reg. grammatikate ja avaldiste uurimisel
Programmeerimiskeelte leksika kirjeldatakse tavaliselt regulaarsete keelte abil. Need on keeled, mida saab kirjeldada (genereerida) regulaarse e. klass-3 grammatikaga (Chomsky klassifikatsioonis), s.t. grammatikaga (T,V,X0,P), mille köik produktsioonid on kujul
X  aY
aY
X a
 V
ja a T
.
V
ja a T
.
Lekseemide (tokens) kirjeldamisel ja nende tunnistajate koostamisel kasutatakse ka teisi formalisme: regulaarseid avaldisi ja lõplikke automaate. Tunnistaja (recognizer) on programm, mis leiab programmi tekstis lekseemid. Regulaarsed avaldised ja lõplikud automaadid on samaväärsed regulaarsete grammatikatega - kui mingit keelt saab kirjeldada ühega nendest formalismidest, siis saab seda kirjeldada ka teistega. Erinevus on nende kasutamises: regulaarsed grammatikad ja regulaarsed avaldised on genereerimismehhanismid, s.t. nad kirjeldavad lekseemide struktuuri; automaat võimaldab kontrollida, kas sellele esitatud märgijada (automaadi sisend) on korrektselt kirjutatud lekseem.
Regulaarsed avaldised ja igale regulaarsele avaldisele e vastav keel L(e), s.t. sõnade hulk terminalide tähestikus T defineeritakse sammude kaupa rekursiivselt:
- tühi sõna λ
on regulaarne avaldis, L(λ) = Ø
(s.t. tühjale sõnale vastab tühi keel);
- iga x T
on regulaarne avaldis, L(x) = {x}
(s.t. vastav keel koosneb ühest ühetähelisest
sõnast);
- kui e1, e2,..., en
on regulaarsed avaldised ja neile vastavad keeled L(e1),L(e2),...,L(en),
siis ka:
1. (e1 | e2 | ... |
en ) on regulaarne avaldis ja L((e1| e2 | ... | en
)) =  L(ei);
L(ei);
2. e1e2...en
on regulaarne avaldis ja L(e1e2...en)
= L(e1)L(e2)...L(en)
(kõikvõimalikud n teguri
korrutised, kus i-s tegur on
keelest L(ei), i=1...n );
3. ei* on regulaarne
avaldis (iga i = 1,2,...,n
korral) ja L(ei*) = L(eij),
j = 0,1,2,...,
s.t. L(ei*) = λ L(e) L(e2)
...
Regulaarsed grammatikad ja regulaarsed avaldised on formalismid
keelte defineerimiseks ja keelde kuuluvate sõnade genereerimiseks
(moodustamiseks). See on tavaliselt inimese jaoks väga arusaadav ja
mõistetav viis, kuid genereerimismehhanismi olemasolu ei taga veel, et
suvalise söna w ja (grammatika
abil esitatud) keele L jaoks
oleks alati selge, kuidas lahendada probleemi: kas sõna w
kuulub keelde L, s.t. w ![]() ? L
? L
Söna keelde kuuluvuse probleemi (aga seda peab arvuti lahendama igas keele teisendusprogrammis, s.t. kõigil transleerimise etappidel) kasutatakse automaate.
Igale grammatikate klassile Chomsky klassifikatsioonis vastab oma automaatide klass.
Regulaarseid keeli saab defineerida ka kui keeli, mida saab tunnistada lõpliku automaadiga. Löplik automaat on viisik (A, S, s0, F, P), kus
A on sisendtähestik
(terminalide tähestik);
S on (lõplik) olekute
hulk ;
s0 S on algolek;
F  S on lõppolekute hulk;
S on lõppolekute hulk;
P on automaadi üleminekuid
(tööd) kirjeldavate produktsioonide hulk. Produktsiooni sa s'
semantika (tähendus) on, et kui automaat olekus s loeb sisendlindilt sümboli
(sisendtähestiku tähe) a, läheb
ta olekusse s' .
Löplikke automaate esitatakse sageli nende graafiga. Automaadi graafi tippudeks on olekud, kaarteks - üleminekud, kaart tähistatakse sisendsümboliga, mis vastava ülemineku esile kutsub.
Näide 1. Täisarvud on sõnad tähestikus T = {0,1,2,3,4,5,6,7,8,9}. Neid kirjeldab:
- regulaarne avaldis(0|1|2|3|4|5|6|7|8|9)*
- lõplik automaat, mille graaf on 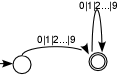 (automaadi graafis
(automaadi graafis  tähistab algolekut,
tähistab algolekut,  - lõppolekut);
- lõppolekut);
- regulaarse grammatikaga, mille ainus mitteterminal on Arv ja produktsioonid on
Arv Arv
0|Arv 1|Arv 2|Arv 3|Arv 4|Arv 5|Arv 6|Arv 7|Arv 8|Arv
9|1|2|3|4|5|6|7|8|9
(Arv Arv
1|Arv 2 ... on lühend produktsioonide Arv Arv 1 ,
Arv Arv 2 ,
...
kokkuvõtlikumaks esitamiseks).
Näide 2. Kui täisarvud ei või alata nulli(de)ga, siis selliseid täisarve kirjeldab
- regulaarne avaldis (1|2|3|4|5|6|7|8|9)(0|1|2|3|4|5|6|7|8|9)*
- lõplik automaat, mille graaf on 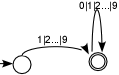 (koosta ise grammatika!).
(koosta ise grammatika!).
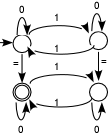 Näide 3.
Grammatika ({0,1,=}, {X0 , Y, Y1
}, X0,
Näide 3.
Grammatika ({0,1,=}, {X0 , Y, Y1
}, X0,
{X0 Y = Y, Y 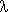 | Y 0 | Y1
1, Y1 Y1 0 | Y 1} )
| Y 0 | Y1
1, Y1 Y1 0 | Y 1} )
genereerib keele { w1 = w2
| |w1|1 = |w2|1(mod 2)},
s.t. kõikvõimalikud jadad kujul w1
= w2 , kus sõnades w1
, w2 on terminali 1
esinemiste arv sama paarsusega (|w|1
tähistab terminali 1 esinemiste
arvu sõnas w), s.t. kas mõlemates
paaris või mõlemates paaritu arv. Selle keele tunnistab kõrvalolev
automaat.
 Mingit
keelt kirjeldavad automaadid, grammatikad ja regulaarsed avaldised ei
ole üheselt määratud ja sageli on (mingis mõttes) minimaalse regulaarse
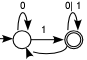
avaldise leidmine keelele üsna raske ülesanne. Näiteks regulaarse
avaldisega (0*1+)*0* kirjeldatud
keele tunnistab kõrvalolev automaat; regulaarse avaldise teise
(vasakult paremale lugedes) iteratsiooni tähistamiseks on automaadis nn
"tühi" üleminek (ilma sisendita). Kuid automaati uurides saab selgeks,
et selle ülemineku võib eemalda, automaadi poolt tunnistatav keel
sellega ei muutu. Kuid ilma selle tühja üleminekuta võib automaadi
poolt tunnistatud keele esitada lihtsamalt: 0*1(0|1)*, seega. (0*1+)*0* = 0*1(0|1)*.
Mingit
keelt kirjeldavad automaadid, grammatikad ja regulaarsed avaldised ei
ole üheselt määratud ja sageli on (mingis mõttes) minimaalse regulaarse
avaldise leidmine keelele üsna raske ülesanne. Näiteks regulaarse
avaldisega (0*1+)*0* kirjeldatud
keele tunnistab kõrvalolev automaat; regulaarse avaldise teise
(vasakult paremale lugedes) iteratsiooni tähistamiseks on automaadis nn
"tühi" üleminek (ilma sisendita). Kuid automaati uurides saab selgeks,
et selle ülemineku võib eemalda, automaadi poolt tunnistatav keel
sellega ei muutu. Kuid ilma selle tühja üleminekuta võib automaadi
poolt tunnistatud keele esitada lihtsamalt: 0*1(0|1)*, seega. (0*1+)*0* = 0*1(0|1)*.
Y = Y ei ole regulaarse grammatika
produktsioon. Teisenda grammatikat, nii et muutuks regulaarseks.
- string on jutumärkide "..." vahele võetud tähtede, numbrite ja keeles lubatud märkide jada, milles ei esine (otse) jutumärgid, kuid võivad esineda interpreteeritavad (nn escape) märgid: \n (reavahetus), \t (tabulatsioon), \" (tähistab stringi teksti kuuluvaid jutumärke), \\ (tähistab stringi teksti kuuluvat märki \ ).
Koosta regulaarne avaldis stringide kirjeldamiseks ja lõplik automaat nende tunnistamiseks.
 Lülitusskeemis kaks
lülitit juhivad sama pirni - vajutus ükskõik kumma lüliti üleval
olevale otsale muudab pirni oleku (põleb, ei) vastupidiseks (tavaline
valgustuskeem näiteks trepil oleva valgust juhtimiseks nii trepi all-
kui ka ülaotsast). Sisendsignaalideks (terminalideks) on v1, p1, v2, p2
(vajutused esimese või teise lüliti vasak- või parempoolsele
otsale); algolekus on mõlema lüliti parempoolne ots üleval ja pirn ei
põle. Keel koosneb kõikvõimalöikest terminalide v1, p1, v2, p2
jadadest, mis panevad pirni põlema (vajutused vöivad olla suvalises
järjekorras lüliti olekust sõltumata), näiteks p1, p2, p1 p1
(viimane vajutus lambi olukorda ei muuda!), p1p2p1v2,
p1v1v1p2, v1v2p2
jne. Leia regulaarne grammatika ja lõplik automaat selle keele
genereerimiseks ja tunnistamiseks.
Lülitusskeemis kaks
lülitit juhivad sama pirni - vajutus ükskõik kumma lüliti üleval
olevale otsale muudab pirni oleku (põleb, ei) vastupidiseks (tavaline
valgustuskeem näiteks trepil oleva valgust juhtimiseks nii trepi all-
kui ka ülaotsast). Sisendsignaalideks (terminalideks) on v1, p1, v2, p2
(vajutused esimese või teise lüliti vasak- või parempoolsele
otsale); algolekus on mõlema lüliti parempoolne ots üleval ja pirn ei
põle. Keel koosneb kõikvõimalöikest terminalide v1, p1, v2, p2
jadadest, mis panevad pirni põlema (vajutused vöivad olla suvalises
järjekorras lüliti olekust sõltumata), näiteks p1, p2, p1 p1
(viimane vajutus lambi olukorda ei muuda!), p1p2p1v2,
p1v1v1p2, v1v2p2
jne. Leia regulaarne grammatika ja lõplik automaat selle keele
genereerimiseks ja tunnistamiseks. T a X | b Y | TT |
X 0 X | 0
Y 0 Y | 1
Kui on, siis koosta lõplik automaat ja regulaarne avaldis selle kirjeldamiseks.
stdout.put( "Hello World", nl );
stdout.puti32(eax, ebx);
stdout.put( I, "-s Fibonacci arv on ", F2:6, nl );
 ©2004-2013 Jaak Henno
©2004-2013 Jaak Henno