Programmeerimine on loomulikus (eesti, vene, inglise) keeles kirja pandud probleemi kirjelduse teisendamine arvutile arusaadavasse vormi, s.t. keelde, mis on oluliselt formaalsem, ei salli kahemõttelisusi, lünki kirjelduses jne. Tavalises, inimeste vahelises vestluses võib rääkija jätta palju asju otse välja ütlemata - vastuvõtja täiendab kuuldut vajalikuga (kuid oma kogemustele vastavalt, sellepärast tekivadki vääritimõistmised). Ideaalne oleks (loomulikult), kui arvuti suudaks otse aru saada loomulikus keeles esitatud probleemikirjeldusest, kuid praegu on see veel üsna kauge perspektiiv, inimene (programeerija koos antud ala spetsialistidega - programmeerija ei tarvitse aru saada näiteks panganduse peensustest) peab ülesande teisendama arvutile arusaadavasse vormi, s.t. programmeerimiskeelde. Vahemik loomulikust keelest arvuti protsessori käskudeni (masinkeel) on üsna pikk ja loomulikus keeles kirjeldatud probleemi teisendamine masinkoodiks nõuab tavaliselt mitu vaheastet, kus probleemi kirjeldatakse erineva ranguse/täpsusega. Erinevate kirjeldustasemete/viiside (kirjelduse vaheastmete) jaoks on loodud väga palju erinevaid programmeerimiskeeli: 2500-3000, kuid arv sõltub näiteks sellest, mida lugeda sama keele dialektiks.
Tavaliselt mõeldakse programmerimiskeeltest rääkides ennekõike nn imperatiivseid (käsu-) keeli: C, Pascal, Ada, Java, Fortran, PHP, Perl jne jne. Need on keeled, mis põhinevad samale ideele nagu arvutite nn von Neumanni arhitektuur: arve säilitatakse pesades/muutujates ja arvutus (programmi täitmine) on pesadele/muutujatele uute väärtuste omistamine; uued väärtused arvutatakse eeskirja/programmi tingimuste alusel praeguste (ja võibolla kusagilt väljastpoolt saadud/loetud väärtuste) põhjal. Need on suhtelist üsna arvutilähedased keeled (vaatamata kasutatavate andmestruktuuride keerulisusele), sest nad eeldavad, et enne programeerimist on täiesti selge, mida tuleb teha, st. ülesanne on analüüsitud ja ülesande kirjeldus (spetsifikatsioon) on esitatud ühemõtteliselt (ranges matemaatilises vormis), nii et programmi on võimalik tõestada, s.t. näidata, et programm vastab spetsifikatsioonile.
 Selline käsustiil on arvutusseadme töö
organiseerimiseks väga loomulik ja seda kasutati ka maailma esimese
arvuti, Babbagge "analüütilise mootori" (analytical engine) töö
kirjeldamisel. Kuigi Babbage arvuti ei valminud, olid selle parameetrid
aukartust tekitavad: aurujõul töötav mehhaaniline seade oleks tulnud
30m pikk ja 10 m lai; see pidid arvutama neljakümnekohaliste (Babbage
viimaste kavandite järgi isegi viiekümnekohaliste) kümnendsüsteemi
arvudega; programmid sisestati perfokaartidelt ja väljundseadmena olid
ette nähtud ka plotter ja kell; programmeerimisel sai kasutada
tingimuslauset ja tsüklit, seega oli arvuti Turing-täielik, s.t.
sellele oleks saanud programmeerida ükskõik millise algoritmi.
Selline käsustiil on arvutusseadme töö
organiseerimiseks väga loomulik ja seda kasutati ka maailma esimese
arvuti, Babbagge "analüütilise mootori" (analytical engine) töö
kirjeldamisel. Kuigi Babbage arvuti ei valminud, olid selle parameetrid
aukartust tekitavad: aurujõul töötav mehhaaniline seade oleks tulnud
30m pikk ja 10 m lai; see pidid arvutama neljakümnekohaliste (Babbage
viimaste kavandite järgi isegi viiekümnekohaliste) kümnendsüsteemi
arvudega; programmid sisestati perfokaartidelt ja väljundseadmena olid
ette nähtud ka plotter ja kell; programmeerimisel sai kasutada
tingimuslauset ja tsüklit, seega oli arvuti Turing-täielik, s.t.
sellele oleks saanud programmeerida ükskõik millise algoritmi.
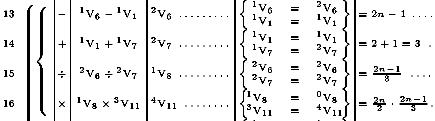
Ülaloleval pildil on väike näide esimese programmeerija, Lord Byron-i tütre Ada Lovelace poolt Babbage arvutile koostatud programmist Bernoulli arvude arvutamiseks. Esimeses veerus on käsu järjekorranumber (sulud tähistavad tsüklit), teises - sooritatav operatsioon, kolmandas - operatsiooni argumendid ja neljandas - kuhu salvestada tulemus; muutuja ees olevad indeksid näitavad selle muutuja väärtuste muutumise sammu, s.t. neljandas veerus olevad tähised on analoogilised praegu programmide semantika selgitamisel kasutatavate eel- ja järeltingimustega (pre- ja postconditions); viiendas veerus on arvutatud valem.
Ka järgmise ajaloolise arvuti, saksa insenerija leiutaja Konrad Zuse poolt 1940-ndatel aastatel konstrueeritud programmeerimiskeel Plankalkül oli puhtalt imperatiivne (seda võib lugeda esimeseks algoritmiliseks keeleks). Selles olid olemas juba enamus tänapäeva programmeerimiskeeli iseloomustavatest omadustest. Zuse töötas sõja ajal Henscheli lennukitehases, kus ta pidi samu valemeid kasutades tegema statistilisi tugevusarvutusi. Korduvate arvutuste kiirendamiseks leiutas ta releedel töötava arvuti Z4; seda arvutit võib pidada esimeseks elektronarvutiks. Sõja lõpus põgenes Zuse Alpidesse ja kasutas sunnitud töötuse oma arvutile programmeerimiskeele loomiseks; Zuse terminoloogias programm oli Rechenplan (arvutusplaan) ja süsteem programmi kirjutamiseks (programmeerimiskeel) - Plankalkül. Zuse arvuti ja programmeerimiskeel töötas kahendsüsteemis (bittidega), kuid bittidest oli võimalik moodustada (ka rekursiivselt) suvalise pikkusega mitmemõõtmelisi vektoreid (arrays) ja kirjeid (records); arvutuste kirjeldamisel sai kasutada protseduure jne. Zuse loodud süsteem (programmeerimiskeel) oli küll raskestiloetav (sisuliselt kahemõõtmeline), kuid kõrgetasemeline, tema näidisprogrammid - Boole valemite süntaksianalüsaator ja malelaual esitatud seisus kuningale lubatava (s.t. kuningat mitte tule alla viiva) käigu leidmine olid tunduvalt keerulisemad kui need, mida (hiljem) kasutati esimese von Neumann-i arvuti testülesannetena.
Imperatiivsed keeled lähtuvad oletusest, et arvutis käsitletakse arve. Kaasaegses elektronarvutis käsitletakse bitte (mis tavaliselt on organiseeritud kaheksa bitti kaupa baitideks); kuidas mingeid bitte/baite tõlgendada - kas täis- või reaalarvudena, tekstina jne - see sõltub interpretatsioonist, mis bittidele/baitidele antakse, arvuti endas (riistvaras) pole see mitte kuidagi fikseeritud. Juba Ada Lovelace esitas, et arvutis toimuvat protsessi võib interpreteerida ka näiteks muusikahelide omaduste teisendamisena, s.t. arvuti võib luua (sõltuvalt selles toimunud arvutuse interpretatsioonist) ka muusikat.
Arvutis toimuvat protsessi võib käsitleda nii: töö algamisel sisestatakse arvutisse bitijada (programm ja algandmed) ja töö lõppedes väljastab arvuti bitijada, milles on (kodeeritud) arvutustulemus, seega kogu arvutamine on tegelikult ühe märgi(biti)jada teisendamine teiseks märgijadaks. Sellist sümbolite teisendamisel põhinevat programmeerimisstiili ja seda kasutavaid programmeerimiskeeli nimetatakse funktsionaalseteks. Imperatiivse programmeerimise tähtsaim element - omistamine - puudub enamuses funktsionaalprogrammeerimise keeltest (nn ranged funktsionaalprogrammeerimise keeled). Funktsionaalprogrammeerimises programm on nimistu (list), mille elemendid võivad olla arvud, sümbolid/stringid, kusagil (mujal) kirjeldatud funktsioonid (funktsioonide nimed) jne; kogu arvutus on selliste sümbolijadade teisendamine. Funktsionaalsetes keeltest programmeerimine sarnaneb matemaatiku arvutustega, kes teisendab valemeid, saades uusi valemeid ja esimeseks funktsionaalprogrammeerimise keeleks loetaksegi sageli loogik Alonzo Church-i poolt 1930-ndatel aastatel loodud lambda arvutust (λ-calculus), kuigi see formaalne matemaatiline süsteem ei olnud üldse loodud arvutis kasutamiseks.
Esimene arvutis kasutamiseks mõeldud funktsionaalprogrammeerimise keel oli IPL (Information Processing language), mille Newell, Shaw ja Simon lõid 1050-ndal aastal arvutile JONNIAC, kuid kogu funkstionaalprogrammeerimise idee tegi tuntuks John McCarthy ideede põhjal 1950-ndate lõpus Massachusettsi tehnoloogiaülikoolis (MIT) loodud programmeerimiskeel LISP (List Processing).
Veidi hiljem ilmus järgmine programmeerimiskeelte pere, kus samuti pole omistamist - nn loogilise programmeerimise keeled, millest tuntuim on Prolog. Prolog-i programm ei kirjelda arvutusi/funktsioone, vaid maailma tõsiasju - mis on tõsi ja mis pole, s.t. siin pole lausetel (Prologi predikaatidel) arvulist väärtust, vaid tõeväärtus - tõene (true) või väär (false). Prologis saab kontrollida, kas muutuja X väärtus on 2*2 (ja kui muutujal X enne ei olnud väärtust, siis X samastatakse väärtusega 4), kuid Prolog-is ei saa omistada X-le väärtust X+1 - selline omistamine on loogiline vasturääkivus.
Imperatiivne ja funktsionaalprogrammeerimine käsitlevad arvuti tööd arvutis toimuva protsessina (teisendatakse arve või valemeid, nimistuid). Prolog-ile on arvuti vaid vahend tegelikku maailma objektide ja nende objektide vaheliste suhete uurimisel, s.t. Prolog-i programm on ennekõikke tegeliku maailma kirjeldus. Prolog-is programmi koostades kirjeldab programmeerija tegelikkuse loogilisi suhteid - mis on tõsi ja mis pole, mis millest järeldub jne ja kui neid suhteid saab ka arvudega iseloomustada, siis leiab (arvutab) programm otsitavad väärtused - kuid kogu arvutusprotsessi käik järeldub programmis kirjeldatud loogilistest suhetest.
Kuid tavaliselt programmeerija teab, milline see arvutuskäik peab olema ja tahab seda "otse" määrata, kuid siiski nii, et see arvutus on seotud vaid teatud kindla tegelikkuse objektiga ja selle sooritamine aitab leida selle objekti mõningaid omadusi. Näiteks isiku sünniaeg (aasta), praegu (käimas olev) aasta ja isiku vanus on omavahel seotud. Prologis võiks seda seost kirjeldada (näiteks) nii:
vanus(Synniaasta, Praegune_aasta, Vanus) :-
Vanus = Synniaasta - Praegune_aasta.
See lause väljendab vaid suuruste Vanus, Synniaasta, Praegune_aasta vahelist suhet (see ei võimalda suurust Vanus arvutada, arvutamiseks peaks ütlema Vanus is Synniaasta - Praegune_aasta) ja seda võib kasutada ükskõik millal. Kuid imperatiivses stiilis programmeerija on huvitatud vaid arvutamisvalemist, kuid võimalike vigade vältimiseks ta ei taha, et seda valemit saaks kasutada kõikjal (imperatiivses stiilis see valem muutub tavaliseks omistamiskäsuks Vanus = Synniaasta - Praegune_aasta). Et anda valemile rangemalt piiratud tähendus, semantika, luuakse objekt - mingit konkreetset tegelikkuse objekti iseloomustavate suuruste ja neid suurusi siduvate arvutusvalemite kogum; objekt-orienteeritud keeles võib näiteks luua objekti (enamuses objekt-orienteeritud keelest nimetatakse objekte klassideks) Isik, millel on omadused Synniaasta ja Vanus; Synniaasta ja Vanus on seotud arvutusvalemida (meetodiga)
Isik.Vanus = Isik.Synniaasta - Date.Year
- siin Date on keeles juba olemas olev (seda pole programmeerijal tarvis luua) klass, mille meetod Date.Year annab käimasoleva aasta. Objekt-orienteeritud ja loogilise programmeerimise keeltes defineeritakse välismaailma (programmis modelleritava ala) jaoks andmestruktuurid (ja vahendid nende manipuleerimiseks, matemaatika terminites - algebrad), mis võimalikult tõetruult püüavad kajastada tegelikkuses toimivaid andmestruktuure ja nendega manipuleerimise viise.Esimene objekt-orienteeritud keel oli 1960-ndate aastate algul Oslos Ole-Johan Dahl-i ja Kristen Nygaard-i loodud Simula. Simula oli algselt mõeldud inimene-arvuti süsteemide käitumise kirjeldamiseks ja uurimiseks (simuleerimiseks), kuid kui valmis selle translaator, muutus uus täiendatud versioon Simula76 kiiresti väga populaarseks kui keel, mille abil oli mugav modelleerida/uurida/programmeerida paljusid probleeme. Simula abil loodi 1970-ndate aastate algul Alan Kay's rühma poolt USA-s Xerox PARC uurimiskeskuses objekt-orienteeritud keeltest kõige tuntuim: Smalltalk.
Prolog, funktsionaalprogrammeerimise ja objekt-orienteeritud keeltes liitub programmi koostamisega ka üsna oluliselt programmeeritava probleemi/ala konseptuaalsest analüüs - millised on selle (s.t. tegelikkuses tomivad) andmekogumid, millised alamosad (klassid) töötlevad informatsiooni ja milliseid funktsioone (meetodeid) nad seda tehes kasutavad. Vea ilmnemisel teeb see üsna segaseks, kus on probleem - kas valesti mõistetud probleemis (viga konseptuaalses analüüsis) või hoopis tegelikkuses toimivast (õieti mõistetud) funktsiooni tõlkimises programmeerimiskeelde. Programmeerimise "puhastamise", s.t. ülesande kirjelduse kahemõttelisustest vabastamise ideel põhineb näiteks programmeerimiskeel Eiffel, kus kogu probleem kirjeldatakse nn sobimustena (contracts), mis kirjeldavad, millised suhted sisend-väljundmuutujate vahel peavad kehtima enne programmi käivitamist (preconditions) ja pärast programmi täitmist (postconditions), s.t. programmi on lihtne tõestada. Kahjuks näitab programmi töestus vaid seda, et programm vastab spetsifikatsioonile. Täiesti korrektse spetsifikatsiooni tegemine (enne programmeerimise alustamist) õnnestub väga harva; tavaliselt tekib/täpsustub arusaamine probleemist just programmeerimise käigus.
Täielikult tegelikkuse andmestruktuuridele toetumine (objekt-orienteeritud programmeerimise ideaal) ignoreerib arvuti füüsilist struktuuri (seniajani von Neumann-i struktuur) ja ennekõike arvutuste organiseerimise praktikat. Arvutamise (translaatorite koostamise, programmide transleerimise) praktika on näidanud, et "arvuti sees" on kõige sagedamini esinevad formaalsed mälustruktuurid kas lõplikud automaadid, s.t. kahemõõtmelised (praegune olek/sisend) tabelid või (keerulisemal juhul) magasinmäluga automaadid, kus andmestruktuur on magasin. Inimese (programmeerija) jaoks on kõige üks kõige arusaadavamaid organisatsioonivorme hierarhia ja arvutusi kirjeldatakse/organiseeritakse tavaliselt just hierarhiliste struktuuride abil. Näiteks aritmeetilise avaldise arvutamine taandub avaldise puu (lõppjärjestuses) läbimisele, kogu programm kirjeldatakse kontekstivaba grammatika abil, mis genereerib puu jne jne. Sellepärast on osutunud väga mugavateks programmeerimiskeeled, kus peamine/ainuke andmestruktuur on magasin; selliste esiisaks võib (vist) lugeda kunagi väga populaarseid HP kalkulaatoreid, mis kasutasid avaldiste/arvutuste sisestamisel nn "tagurpidi poola kuju". Sellistest keeltest tuntuim on kahtlemata Forth, kuid magasini kasutamisel põhineb ka tuntud graafikafirma Adobe poolt loodud trükiste formaadikirjelduskeel (printeritele) Postscript. Järjekindel magasini kasutamine võimaldab (peaaegu) loobuda omistamisest, arvutused ja transleerimine on väga kiired - andmed on tavaliselt alati magasini tipus, s.t. neid ei pea hakkama mälust otsima, interpretaator/translaator tuleb väga väike (tavaliselt alla 500 KB), programmid töötavad minimaalse (paarikümnekilose) interpretaatoriga ükskõik millises keskkonnas (DOS/Windows, UNIX, Apple); programm on laiendatav ja selletõttu pole programmeerimisel tavaliselt üldse tarvis erilist debuggerit/arenduskeskkonda jne. Forth on ka väga mugav translaatorite "tagumise otsa" (back end) kirjeldamise keel, s.t. abstraktse süntaksi puust (AST) kompileeritud programmi saamise etapi programmeerimiseks; selliselt oli realiseeritud Tartu ülikoolis 80-ndate keskpaiku prof Mati Tombaku juhtimisel realiseeritud translaatorite genereerimise süsteem.
Forth-i ideel - kogu programmi ainuke andmestruktuur on magasin (tegelikult kasutab translaator veel vähemalt üht, nn tagasipöördumis(return)-magasini) on loodud mitmeid väga väikesi ja kiireid keeli (Joy, vt ka http://www.latrobe.edu.au/philosophy/phimvt/joy/j01tut.html , http://www.latrobe.edu.au/philosophy/phimvt/joy.html ), mida kasutatakse kõige erinevamates valdkondades, süsteemiprogrammeerimisest mängude tegemiseni (vt näiteks Win32Fort-iga kaasa antud 3D-maleprogrammi näidet) .
Palju erinevusi on ka programmeerimiskeelte tasemes. Nn madala taseme (low-level) keeltes programeerija pääseb (sageli peab) tegelema otse arvuti mälupesa tegelike/füüsiliste aadressidega, nagu näiteks C-s. Nn kõrgtaseme keeltes (alates Fortran-ist) programeerija tegeleb vaid muutujate nimedega, muutujate paigutamine mällu (arvuti mälupesade varumine) ja kasutuks muutunud muutujate poolt hõivatud mäluosade vabastamine (prahikoristamine - garbage collection) jääb translaatorile. Enamuses kaasaegsetest kõrgkeeltest on mäluvarumine ja prahikoristamine täielikult automatiseeritud, kuid võimalikult effektiivse programmi saamiseks on ka mõnedes kõrgkeeltes olemas võimalused otse mälupesade ja -bittide käsitlemiseks (näiteks Ada-s).
Kuid peale muutujate kasutatakse programmeerimises (ja matemaatikas) palju keerulisemaid (kõrgemat järku) salvestusstruktuure - näiteks programmeerimiskeele APL (A Programming Language) peamised andmestruktuurid on vektorid (arrays) ja maatriksid. Kuna maatriksoperatsioonid (ja teised APL operatsioonid) sisaldavad paljusid "tavalisi" liitmisi-lahutamisi-korrutamisi-jagamisi, on APL programm palju "võimsam", s.t. sama eesmärgi saavutamiseks tuleb programm palju lühem kui C-s või Java-s kirjutatud programm. Näiteks nimistu elementide keskmise arvutamise programm koosneb vaid kümnest märgist:
{(+/ω)÷ρω}
Siin ω on funktsiooni argument (nimistu), +/ω - nimistu elementide summa, ρω - nimistu pikkus ja ÷ - tavaline jagamine. Selline äärmine askeetlus märkide kasutamises andis APL-i-le väga innuka kasutajaskonna, ja esimese versiooni veidrustele ( kasutas sümboleid, millest enamikku tavalisel klaviatuuril üldse pole!) kasutatakse keelt innukalt. Veel lühem on sama programm APL-keele järglases, J-keeles:
(+/%#)
J-s on ära jäetud argumendi tähistamine (nagunii on arusaadav!), nimistu pikkust arvutab # ja jagamist tähistab % .
Paljud kaasaegsed programmeerimiskeeled kasutavad nn 'kõrgemat järku' funktsioone, mille argumendiks võib olla funktsioon (mitte staatiline andmestruktuur). Matemaatikas on selline funktsioonidega opereeriv operaator näiteks tuletis - sisendiks on funktsioon, väljundiks taas funktsioon (sisendi tuletis). Sellised funktsionaalse argumendiga operaatorid on tavalised funktsionaalsetes programmeerimiskeeltes (Scheme) kuid sellised (funktsioonid) on sageli väga loomulikud/vajalikud. Näiteks nimistu (massiivi) järjestamisel on oluline selle elementide tüüp (nende hulgal defineeritud järjestus) - täis/reaalarvude järjestus erineb stringide järjestamisel kasutatavast leksikograafilisest järjestusest; stringe ja arve koos kasutatavates massivides (kaasajal näiteks failinimed sageli enam ei alga tähega) tuleb defineerida ka stringide ja arvude võrdlemise tulemus, seega järjestamisalgoritmi üheks sisendparameetriks peaks olema massivi kahe elemendi võrdlusalgoritm - selline on näiteks C-keele qsort . Kõrgemat järku funktsiooni näiteks on ka paljudes programmeerimiskeeltes kasutatav eval (evaluate - soorita) , mis võtab argumendiks stringina esitatud funktsiooni nime, seega selle saab arvutada alles programmi täitmise ajal; neid kasutatakse paljudes kaasaegsetes imperatiivsetes keeltes (C#).
Programmeerimiskeeli võib liigitada väga mitmel viisil, näiteks vaba sõnaraamat esitab (vähemalt) järgmised klassid:
Selle liigituse printsiibid on veidi segased (mis on "Educational Programming language"?), kuid nii on vist iga liigitusega; veidi suurem ülevaade programmeerimiskeeltest (2500 keelt) kasutab 20-t kategooriat.
Vaatamata erinevate programmeerimiskeelte üsna erinevatest lähtekohtadest, on neist enamus loogiliselt samaväärsed (universaalsed) - kui mingit probleemi saab lahendada mingis keeles kirjutatud programmiga, siis saab seda lahendada ka teises keeles kirjutatud programmiga, s.t. need programmeerimiskeeled on samaväärsed Turing-i masinaga ehk Turing-täielikud. Turing-täielikkuse jaoks pole üldse vaja keerulisi funktsioone ja juhtimiskonstruktsioone: saab näidata, et kui keeles on olemas täisarvude võrdlemine (s.t. operaator ==, mille tulemus on true või false) täisarvude lahutamine ja if-then-goto konstruktsioon (goto jaoks peab saama kasutada ka märgendeid), on keel täielik.
Kuid mõne probleemide valdkonna jaoks on loodud ka nn" väikesi" keeli (little languages), mis pole universaalsed, s.t. neis ei ole võimalik kirjutada kõiki programme, nad sobivad vaid oma (suhteliselt kitsa) probleemide valdkonna jaoks. Näiteks nn "Neljanda põlvkonna keeled" (4th generation languages, 4GL) on mõeldud enamasti tööks andmebaasidega ja nende süntaks on tunduvalt lähedasem loomulikule keelele. SQL-is kirjutatud päring:
FIND ALL RECORDS WHERE NAME IS "SMITH"
on arusaadav ka mitteprogrammistile. Vastava päringu koostamine näiteks C-s nõuaks andmete salvestusformaadi tundmist (kuidas kirjed on salvestatud, kus kirjes paikneb väli "NAME" ja (võibolla mitut) tsüklit, ja tulemuseks saadavas programmijupi põhjal võib olla peaaegu võimatu otsustada, mida see üldse peab tegema, näiteks tunnuse nimi "NAME" võib üldse puududa, kui selle asemel on kasutatud välja indeksit.Vastupidi, näiteks kahemõõtmelises keeles BEFUNGE (kahemõõtmelisi keeli kasutatakse näiteks tasandiliste rakuautomaatide programmeerimisel) kirjutatud programm ei "reeda" oma otstarbest mitte midagi:
vv < <
2
^ v<
v1<?>3v4
^ ^
> >?> ?>5^
v v
v9<?>7v6
v v<
8
. > > ^
^<
- see programmijupp genereerib juhuslikke arve.
Kuigi programmeerimiskeeled pole nende olemasolu viiekümne aasta jooksul eriti palju muutunud, on siiski märgata loomulikele keeltele lähenemise tendentsi. See on täiesti loomulik: iga probleemi lahendamine algab probleemi kirjeldamisega loomulikus keeles; alles siis, kui probleemist on täielikult aru saadud, selle sisu on (loomulikus keeles) "lahti harutatud", s.t. pärast probleemi konseptuaalset analüüsi võib hakata ülesannet järk-järgult arvutile arusaadavaks tegema, s.t. programmeerima: algul mingi kõrge taseme formalismi abil (UML skeemid) ja siis järk-järgult programmeerides.
Hea näide loomulikule keelele lähenemisest on nn "neljanda põlvkonna keeled", millest tuntuim näide on andmebaaside päringukeeled, näiteks SQL. Kuna päringu võib esitada kujul, mis meenutab loomulikku keelt:
FIND ALL RECORDS WHER NAME IS JUKU
siis tekib mulje, et siin arvuti juba saab aru peaaegu loomulikust keelest. Tegelikult ei saa arvuti (endiselt) millestki aru ja see rida on peaagu puhas Cobol: - peamine erinevus on, et Cobol oli fikseeritud struktuuriga andmefailide jaoks.
.
(magasini tipu näitamine)
: ( uue sõna defineerimine ja
selle kasutamine)
var - muutuja deklareerimine
! - muutujale väärtuse omistamine
& - muutuja kasutamine
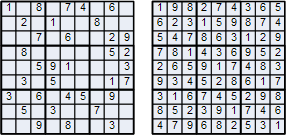 Sudoku on Jaapanist pärit nuputamismäng:
esialgne
osaliselt täidetud 9 x 9 ruudustik tuleb täita numbritega 1,...,9 nii,
et igas reas, veerus ja kõigis üheksas 3x3 kastis esineks kõik numbrid
1..9 (kõrvaloleval joonisel on algul ülesanne ja selle kõrval -
lahendus.
Sudoku on Jaapanist pärit nuputamismäng:
esialgne
osaliselt täidetud 9 x 9 ruudustik tuleb täita numbritega 1,...,9 nii,
et igas reas, veerus ja kõigis üheksas 3x3 kastis esineks kõik numbrid
1..9 (kõrvaloleval joonisel on algul ülesanne ja selle kõrval -
lahendus.
Järgnevas on Sudoku-d lahendav programm APL-is - koosta sama programm oma lemmik-programmeerimiskeeles!
j =. (]/. i.@#) ,{;~3#i.3
r =. 9#i.9 9
c =. 81$|:i.9 9
b =. (,j{9#i.9) { j
I =: ~."1 r,.c,.b
R =: j,(,|:)i.9 9
regions=: R"_ {"_ 1 ]
free =: 0&= > (1+i.9)"_ e."1 I&{
ok =: (27 9$1)"_ -:"2 (0&= +. ~:"1)@regions
ac =: +/ .*&(1+i.9) * 1: = +/"1
ar =: 3 : 0
m=. 1=+/"2 R{y.
j=. I. +./"1 m
k=. 1 i."1~ j{m
i=. ,(k{"_1 |:"2 (j{R){y.) #"1 j{R
(1+k) i}81$0
)
assign =: (+ (ac >. ar)@free)^:_"1
guessa =: 3 : 0
if. -. 0 e. y. do. ,:y. return. end.
b=. free y.
i=. (i.<./) (+/"1 b){10,}.i.10
y. +"1 (1+I.i{b)*/i=i.81
)
guess =: ; @: (<@guessa"1)
sudoku =: guess @: (ok # ]) @: assign ^:_ @ ,
see1 =: (;~9$1 0 0)&(<;.1) @ ({&'.123456789') @ (9 9&$) @ ,
see =: <@see1"1`see1@.(1:=#@$)
diff =: * 0&=@}:@(0&,)
 ©2004-2013 Jaak Henno
©2004-2013 Jaak Henno