Keel on kommunikatsioonivahend, meetod informatsiooni edastamiseks. Märgisüsteemi (keel) abil millegi edastamiseks on tarvis algul kokku leppida, milliste märkidest moodustatud struktuuridega seda tehakse - on tarvis määrata keele süntaks. Süntaks määrab keele formaalse kuju, vorm. Programmeerimiskeele süntaks määrab näiteks, kuidas kirjutatakse if-lause - kas sõna then on kohustuslik, kas if-lause lõpeb mingi lõpumärgendiga (endif), kas iga käsu lõpus peab olema mingi eraldaja (Javascript - eraldaja pole vajalik, kui järgnev käsk on uuel real; Prolog-is peab iga predikaadi lõpus olema punkt) või peab olema eraldaja käskude vahel (Pascal - viimase käsu järel ei ole eraldajat), kas tingimuslauses tingimuse ümber peavad olema mingid eraldajad (C-s - sulud) või mitte jne. Süntaksi kirjeldamisel kasutatakse programmis esinevaid kõige väiksemaid jagamatuid märgijadasid: arve, identifikaatoreid, keele võtmesõnu (if, then,...) - need on lekseemid (tokens) ja nende õigekirjareeglid moodustavad keele leksika: milliseid märke programmi tekstis üldse võib esineda, kuidas kirjutatakse identifikaatorid, kui pikad nad võivad olla jne), kuidas kirjutatakse arvud (millise kujuga võivad olla reaalarvud) jne.
Süntaks annab programmeerimiskeelest esimese mulje - kui arusaadav ja loogiline keel on, kuivõrd see sarnaneb loomulikule keelele ja kui vähe (või palju) kasutatakse selles nn "süntaktilist suhkrut" (syntactic sugar) - sulge, semikooloneid jne mis on vajalikud vaid translaatorile programmi struktuuri kindlakstegemiseks ja mis (tavaliselt) suurendavad programmeerimisel tekkivate süntaksivigade arvu. Järgnevas on programm, mis väljastab täisarvude 1..10 ruudud, esitatud mitmes erinevas programmeerimiskeeles - milline neist näib arusaadavam ja lihtsam, s.t. kasutajasõbralikum?
A+ - APL-tüüpi vaba programmeerimiskeel, levitatakse GNU GPL (General Public Licence) alusel:
(1 + 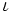 10)*2
10)*2
moodustab vektori,
s.t. 10 on vektor 1..10; C++
|
#include <iostream> using namespace std; int main() { int square[100]; int i; /* loop index */; int k; /* the integer */ /* Calculate the squares */ for (i = 0; i < 100; i++) { k = i + 1; /* i runs from 0 to 99 */ /* k runs from 1 to 100 */ square[i] = k*k; cout << "The square of " << k << " is " << square[i] << endl; } return 0; } |
K - unikaalne vaba programmeerimiskeel Windows ja Solaris/Linux operatsioonisüsteemile; ühendab endas APL-i ja funktsionaalsete programmeerimiskeelte jooni; väga kõrgetasemeliste funktsioonide tõttu osutus testprogramm, mis Visual Basic-us oli 200-realine ja Java-s 350-realine, K-s kirjutatuna vaid 9-realiseks ja umbes sada korda kiiremaks
i:1 + !10
`0:5:i*i
Programmeerimiskeelte süntaksit vaadetes tekib sageli tunne, et keelte loojad ei mõtle eriti palju keele sõntaksi loomulikkusele ja sageli mingid põhimõtted, näiteks "objekt-orienteeritus" on palju olulisemad kui terve mõistus. Suurte rahadega (tellija: USA kaitseministeerium) ja käraga (rahvusvaheline kahe-etapiline konkurss) loodud rogrammeerimiskeele Ada 1983.a manuaal algas sõnadega "Syntax summary is not part of standard definition of Ada programming language" - s.t. Ada süntaksil pole üldse standardit ja programmide (süntaktiliselt) korrektse kuju peavad keele kasutajad (programmeerijad ja translaatori kirjutajad" välja uurima keele kirjelduses esitatud näidetest ja tekstina esitatud kirjeldustest ja piirangutest, mis sageli olid ebatäielikud ja segased. Ada süntaksit on raske meeles pidada, sest sisuliselt lähedased konstruktsioonid kirjeldatakse sageli erinevalt:
- tüübi- ja alamtüübideklaratsioonides kasutatakse sõna IS :
type COLOR is (WHITE, RED, Yellow, GREEN, BLUE,
BROWN, BLACK);
subtype RAINBOW is COLOR range RED..BLUE;
- kuid ülesanded (task) deklareeritakse täiesti erineva süntaksi abil:
task type RESOURCE is
entry SEIZE;
entry RELEASE;
end RESOURCE;
- semantiliselt lähedastes objekti- ja konstandidefinitsioonides on sõna IS asemel koolon : ; objektikirjelduses puudub kirjelduse liiki määrav sõna (type), kuid konstandikirjelduses on see nihkunud erinevale kohale:
C1, C2 : COLOR; B : constant COLOR := BLACK;
Ja ka kogenud programmeerijale jääb arvatavasti ebaselgeks, mida peaks tähendama deklaratsioon:
OPTION: BIT_VECTOR(1..10) := (others => TRUE);
Palju programmeerijasõbralikuma süntaksi saaks neid versioone ühtlustades, s.t. kui muutujaid ja konstante võiks ka deklareerida näiteks kujul :
var C is COLOR;
constant R is COLOR := RED;
Tüübi, konstandi ja objektideklaratsioonid keeles C++ on enam-vähem sarnased:
typedef int Boolean;
const Boolean TRUE = 1;
Kuid täiest "teisest ooperist" on võimalus deklareerida kirje (struct) tüübiga muutujaid tüübideklaratsiooni järel (see komplitseerib ka süntaksianalüüsi):
struct Student
{
String20 nimi;
int matriklinumber;
} stud1, stud2;
Kaasaegsed arvutid ja translaatorite tegemise tehnoloogia on juba ammu nii hea, et keeltes võiks lubada süntaksi variatsioone, s.t. näiteks ülalesitatud Ada deklaratsioonid võiks kõik olla lubatud (mingit mitteühesust ei teki); peale nende võiks olla lubatud ka näiteks sellised vormid:
var C1,C2,C3 are COLORS;
variables C1, C2 : COLORS;
Võiks arvata, et programmeerimiskeeled muutuvad arengu käigus lihtsamaks, loomulikumaks- see teeks programmid kergemini arusaadavamateks ja kiirendaks/lihtsustaks programmeerimist. Kuid "objekt-orienteerituse hullustus" on muutnud C-keeles kolmerealise programmi
main()C++-s ja C#-s juba peaaegu kaks korda pikemaks:
{
printf("hello, world\n");
}
#include <stdio.h>
int main(void)
{
printf("hello, world\n");
return 0;
}
Miks ei võiks C# translaator olla nii tark, et programmi tekstis sõna printf kohates automaatselt liidaks sisend-väljundteegid, s.t. sooritaks ise rea #include <stdio.h> ja miks ei võiks translaator oletusena iga protseduuri lõppedes väljastada väärtuse 0, kui protseduur ise midagi ei väljasta? Mõned programmeerimiskeeled siiski juba taipavad ja teevad nii, näiteks Java virtuaalmasinal töötav assembler Jasmin.
Veel "teaduslikum" on tekstirea väljastamine Javas; kui C-s pidi programmeerija meeles pidama vaid üht reserveeritud sõna, siis siin on neid juba 10 (ka suur- ja väiketähed peavad olema täpselt õiges kohas!), lisaks veel neli paari sulge:
class HelloWorld {
public static void main(String[] args) {
System.out.println("Hello World!");
}
}
Ka siin on avalikes (open source) keeltes juba üht-teist loomulikkuse suunas tehtud, näiteks Java VM-il töötavas skriptikeeles Groovy võib lihtsalt kirjutada
println("Hello World!");
Mõned C, C++ ja Java süntaksi jooned on pigem vead. Kõigis loogika formalismides on konjunktsiooni (C-s: && ) ja disjunktsiooni || prioriteet kõrgem kui ekvivalentsi == prioriteet, s.t. matemaatikas ja lausearvutuses (0 & 1 == 0) = ((0 & 1) == 0) = (0 == 0) = 1 (siin = on tavaline matemaatiliste/loogiliste avaldiste võrdumine, kuid C-s on ekvivalentsi == (ja ka selle eituse !=) prioriteet kõrgem, seega C-s, C++-s ja Javas (0 & 1 == 0) = (0 & (1 == 0)) = (0 & 0) = 0 - kas need keeled tahavad ümber defineerida sajanditepikkuseid matemaatilisi traditsioone? Stringide ja viitade käsitlemine C-s võib hulluks ajada ka üsna kogenud programmeerija - kes arvab, et oskab C-d ja see on käkitegu, püüdke C-sse tõlkida eespool esitatud Pisi-Algoli translaator HLA-sse (Antlr+Java) - kuidas C-s genereerida vahemuutujaid, stringe "T"+atoi-1(n), kus n on täisarvuline muutuja ja atoi-1 - C-funktsiooni atoi pöördfunktsioon (s.t. teisendab täisarvu samasuguse väljanägemisega stringiks) ja kuidas genereerida samasugusei märgendeid ja teha seda nii, et kõik aru saaksid?
C süntaksi veidrustesse kuuluvad ka omistamise-operatsiooni ühendamised, s.t. operaatorid +=, =+ jne. Need on väga kasulikud, sest võimaldavad translaatoril kirjeldada operatsioonide järjest sooritamine protsessoris, nii et ülearused protsessor-RAM infovahetused ära jäävad. Kuid omistamismärgist paremal pool olev + või - kipuvad segamini minema järgneva avaldise märgiga - : mis on järgmiste käskude tulemus (erinevus on tühikute paigutuses):
x = -10;
x =- 10;
x =-10;
Peaaegu kõigi imperatiivsetes keeltes on olemas on globaalsed muutujad - muutujad, mis on kõikjal kasutatavad. Kõik saavad aru sõnast global, kuid C-s on neid dekalreeriv võtmesõna extern - taas midagi mitte endastmõistetavat, mille C programmeerija peab meeles pidama. Java juurdepääsumeetodi (access) deklareerimismeetod - public, protected, private peavad olema deklaratsioonis märgitud, kuid meetod package deklareeritakse deklareeriva sõna puudumisega, mis on arusaamatu ja tekitab kergesti vigu, sellepärast on mõnes Java kursuses esitatud lisanõue - kõik väljad (fields) ja meetodid peavad olema kindlasti deklareeritud kas public, protected või private meetodiga.
Arusaamatu on, miks peaaegu kõigis imperatiivsetes keeltes kasutatavad ja seetõttu enamusele programmeerijatest enesestmõistetavad võtmesõnad const, goto on Javas reserveeritud (neid ei tohi kasutada identifikaatoritena), kuid neid ei kasutata - const asemel peab kasutama final ja goto asemel break. Sõna static kasutatakse tähenduses, mis sugugi ei vasta selle tähendusele inglise keeles (staatiline, liikumatu), Javas tähendab static (umbes) "unikaalne" - kui klassi liikme on deklaratsioon on static, siis on tal vaid üks koopia, mida kõik instantsid jagavad (tavalistel liikmetel on iga instantsi jaoks oma koopia). Arvude võrdlemisel kasutatakse operaatorit ==, kuid stringide võrdlemisel peab C-s kasutama strcmp(str1,str2) ja Javas veel kummalisemat ebasümmeetrilist vormi str1.equal(str2). C ja C++ süntaksit on ammu kritiseeritud - miks pidi Java seda jälgima, suurendades segadust veelgi?
Raske on mõista ka Java nõuet, et iga klass peab olema salvestatud eraldi failis ja failinimi peab täpselt kokku langema klassi nimega. Kui näiteks failis hello.java on defineeritud klass Hello, siis Java kompilaator javac komileerib selle, kuid kui seda tahetakse käivitada, tuleb veateade:
C:\mywork>java Hello.class Exception in thread "main" java.lang.NoClassDefFoundError: Hello/class
Kui translaator klassi on kompileerinud, siis ei tohiks (kompileeritud!) klassi failinimel enam olla mingit tähtsust, sest käivitatakse klassi peameetod main - kui see on failis olemas, siis peaks kõik toimima, kahe samasuguse nime kasutamise nõue (failinimi peab kokku langema klassi nimega) on vastuolus programmeerimise ühe põhitöega - iga informatsioon kirjeldatakse vaid üks kord ühes kohas (muidu on programmide modifitseerimine väga raske).
Raske on mõista ka nõuet: "The command to run the Java interpreter should use the class name but should not include any extension, neither .java nor .class. An extension in the file name confuses the interpreter about the location of the class (the extension is interpreted as a subfolder)."
Kas seda kergesti segadusse sattuvat interpretaatorit ei ole võimalik veidi arukamaks ja ühtlasi töökindlamaks teha? Java interpretaatori java argument on (kompileeritud) meetodi (s.t. täidetava programmi) nimi (siin: Hello); kuidas saab programmi nime osa tõlgendada alamkataloogina? Veel segasemaks läheb asi pakettide nimedega - kui firma hobnob.com programmeeerib graafikapaketti graphics, siis peaks selle nimi olema package com.hobnob.graphics, ja Sun põhjendab seda nii: "Because you need to manage source and class files in this manner so that the compiler and the Java Virtual Machine (JVM) can find all the types your program uses" - Sun-i arvates tähtis on translaator, mitte inimene. Näib, et Java tegijad pole veel kuulnudki sellest, et arvutite võimsus kahekordistub keskmiselt iga pooleteistkümne aastaga (Moore seadus), kuid inimeste (programmeerijate) ajumaht ei suurene. Programmid ja programmide tegijad peaks ennekõike mõtlema inimese mugavusele. Llihtne oleks teha translaator veidi arukamaks (ja ka kiiremaks, javac on üks aeglasemaid Java translaatoreid) muuta; juba ongi olemas kümneid (vabasid) Java translaatoreid (vt loetelu lk-l http://www.thefreecountry.com/compilers/java.shtml), millest mitmed on tunduvalt kiiremad ja annavad ka rohkem veateateid (näit Jikes on väidetavalt umbes kümme korda kiirem ja annab ka rohjem veateateid).
Java teeb isegi täiesti elementaarsed toimingud süntaktiliselt nii segaseks ja keerukaks, et algajal programmeerijal on väga raske nendega toime tulla. Kuidas (näiteks) sulgeda programm (lõpetada selle täitmine)? Algaja programmeerija võib arvata, et piisab reast
exit
kuid Java-s peab defineerima meetodipublic static void exit(int status)
Algajale see tundub kindlasti segane ja keeruline, eriti kui ta loeb Java veebimanuaalist (on-line) (http://java.sun.com/j2se/1.4.2/docs/api/java/lang/System.html#exit(int)): This method never returns normally - kas see tähendab, et pärast selle kasutamist hakkavad Teie arvutis toimuma mingid mittenormaalsed protsessid - viirusi tuleb kui Vändrast saelaudu, Luke Skywalker vehib ekraanil nende tõrjumiseks lasermõõgaga jne ? Loomulikult kahtleb vähekogenud programmerija, kas ta üldse julgeb selliseid vaime välja kutsuda ja üritab midagi lihtsamat.
Manuaali järgmisel real selgitatakse: " The call System.exit(n) is effectively equivalent to the call:
Runtime.getRuntime().exit(n)
- asi läheb veel segasemaks, sest kusagil pole öeldud, kasSystem.exit(n)
on samaväärne manuaalis esimesena esitatud reagapublic static void exit(int status)
või tuleb kutsuda süsteemifunktsiooniRuntime.getRuntime().exit(n)
ja mida tähendab "effectively equivalent" - kas see on täpselt samaväärne või on eriliselt effektiivselt samaväärne (kuid täpselt ei ole)?Miks peab inimene (programmeerija) meeles pidama sellist süntaksit (suur- ja väiketähed on erinevad!) - meil on niigi tarvis meeles pidada väga palju süntakseid, koode, protokolle, ligipääsunumbreid- ja stringe jne jne ?
Arvuti ja programmid (kompilaatorid) peaks aitama inimest, s.t. programmeerijat. Väga sageli on süntaksivea semantikast (s.t. reast, kus see viga ilmneb) 99% tõenäosusega selge, mida programmeerija (inimene) tegelikult mõtles. Arvuti (programm, kompilaator) peaks sellisel juhul automaatselt vea parandama või pakkuma paranduse, kuid enamus kompilaatoreid (ka Java) uhkeldavad sellega, et sunnivad programmeerijat parandama elementaarseid "näpukaid". Ka siin on "ühe-mehe-keeled" sageli paremad, näiteks HLA interpretaator esitab sageli sõbraliku soovituse "kas Sa ei mõelnud mitte seda: ...".
Java, C, Ada pole (kahjuks) erandid; paljudes keeltes leiutatakse "oma" süntaksit, mis erineb üldkasutatavast ja raskendab meeldejätmist. Enamuses käsukeeltest (C ja selle järglased) kasutatakse loogelisi sulge {...} käskude bloki eraldamiseks (Algol-Ada-tüüpi keeletes kasutatakse selle asemel begin... end), kuid Turbo-Pascalis on {...} kommentaarieraldajad, eespoolvaadeldud println("Hello World!") asemel peab Smalltalk-i kaasaegses versioonis Squeak ütlema Transcript show: 'Hello World' ja mitte kasutama jutumärke, sest jutumärgid on kommentaarieraldajad!
Kui programmeerimiskeele süntaks on selge, peab teadma ka seda, mida süntaksiga lubatud kontruktsioonid tähendavad ja teevad, s.t. milline on keele semantika.
Programmeerimiskeele loojate ja kasutajate jaoks on olulised ka keele praktilise kasutamise aspektid, keele pragmaatika - milliste ülesannete lahendamiseks üks või teine keel on mõeldud, kui mugav keel on kasutajale, kui kiire on keele translaator/interpretaator jne. Näiteks C (C++, C#) on väga kiired, kuid nendes programmeerimine on üsna vaevaline, sest selle pere keeled on kõik väga arvutilähedased ja neid puuduvad paljud kaasaja kõrgkeeltes esinevad konstruktsioonid (C-s puudub isegi stringitüüp, kuid kaasaegne Internet-programmeerimine on sageli just tekstide käsitlemine) ja kuna translaator peaaegu midagi ei kontrolli, siis võivad kergesti tekkida vead ja programmidesse turvaaugud; Java on universaalne (selles kirjutatud programmi peaks saama kasutada ükskõik millises operatsioonisüsteemis), kuid kaheastmelise transleerimise tõttu üsna aeglane. Ada translaator kontrollib peaaegu kõike, mida translaator üldse saab kontrollida, sellepärast kasutatakse Adat kriitiliste süsteemide (näiteks raketi- ja lennujuhtimissüsteemid) programmeerimisel, kuid kontrollid teevad programmi täitmise aeglaseks ja sellepärast olid need välja lülitatud, kui Ada-s koostatud raketijuhtimissüsteem 4 juunil 1996 põhjustas raketi Ariane 5 plahvatuse - see oli üks kõigi aegade kallemaid tarkvara poolt põhjustatud õnnetusi. Mitmed programmeerimiskeeled on spetsiaalselt koostatud tulevast kasutusala silmas pidades, näiteks Cobol koostati raamatupidajatele, Prolog oli algselt mõeldud loomuliku keele analüüsiks; mitmed programmeerimiskeeled (Logo, Basic, Pascal, Alice) on loodud programmeerimise õpetamiseks, sellepärast on nad lihtsa süntaksiga, s.t. sobivad algajatele, kuid neis puuduvad paljud kaasaja kõrgkeeltes kasutatavad andmestruktuurid jne.
Keele süntaksi ja semantika peab esitama väga täpselt, sest programmeerimiskeele süntaksi ja semantika kirjeldus on aluseks translaatori koostajatele - ükskõik millise translaatoriga transleerides ja ükskõik millises operatsioonisüsteemis käivitades peab programm andma sama tulemuse. Süntaksi kirjeldamiseks kasutatakse tavaliselt kontekstivabasid grammatikaid ja nende erikujusid: BNF, EBNF, RBNF.
Esimene mulje programmeerimiskeelest saadakse selle süntaksist - kui arusaadav keel näib, kuivõrd see sarnaneb loomulikule keelele ja kui vähe (või palju) kasutatakse selles nn "süntaktilist suhkrut" (syntactic sugar) - sulge, semikooloneid jne mis on vajalikud vaid translaatorile programmi struktuuri kindlakstegemiseks ja mis (tavaliselt) suurendavad vaid programmeerimisel tekkivate süntaksivigade arvu. Sulge loetakse ( tavaliselt) täiesti mitte eriti selgitusi vajavaks süntaksi osaks, kuid paljudes keeltes ei ole sulgude kasutamine päris enesestmõistetav. Järgnevas on mõned süntaktiliselt korrektsed näited sulgude kasutamisest erinevates keeltes (selgitus on programmilõigu lõpus); millised neist näivad loomulikud ja kasutajasõbralikud/arusaadavad, millised mitte:
Lisp (rekursiivne programmi faktoriaali arvutamiseks:
(defun faktoriaal (x)- kandiline sulg programmi lõpus suleb kõik eespool avatud "ripakil olevad" (sulgemata) sulud; lubatud on ka lihtsalt lisada (huupi) niipalju sulgevaid sulge, kui näib olevat vajalik, ja siis kindluse mõttes veel mõned - translaator ei pahanda.
(if (eql x 0)
1
(* x (faktoriaal (- x 1)) ]
Ada:
<<Tule siia! >>
- märgend !HTML:
<!-- Script: -->
- kommentaar.XML:
<![IGNORE[- ka see on kommentaar (XML-is võib kasutada ka HTML-süntaksiga kommentaare, kuid need on kuidagi liiga lihtsad...).
See on vist jama ...
]]>
XML DTD:
<!ELEMENT nimi (#PCDATA)>
- elemendi ja selle andmetüübi deklaratsioonid. ©2004-2009
Jaak
Henno
©2004-2009
Jaak
Henno