Machine learning vs human learning
Experiments in NLP (Natural Language Processing)
Jaak Henno, Tallinn University of Technology, Estonia
Hannu Jaakkola, Tampere University of Technology, Pori
Jukka Mäkelä, University of Lapland, Rovaniemi, Finland
This presentation is on-line at http://staff.ttu.ee/~jaak.henno/Mipro2021/
Language (English, Croatian, Estonian - all 'Natural Languages') is the most powerfull tool created by Humanity. Languge/communication rised humans over all other animals and made us 'the Kings of our Planet'
But into our human communications has entered a new powerful participant - computer
On Internet, we often speak with computers - believing that our conversation partner is human

Computers can already create new texts/paintings/songs which are indistinguishable from human-created ones
Many text analyzing and classication tasks (spam and plaguarism, hate speech e.g. detection) are routinely handled by programs
More than half of Twitter tweets are generated by a program
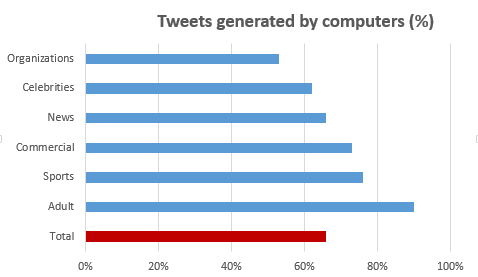
More than half of climate/vaccine denial tweets are computer-generated:

Everyone can make a bot for automatically creating Twitter tweets

or download such bot for nothing
Computer-generated novels are sold on Amazon like ordinary books (with similar prizes):

Everyone can download a program to produce
new Shackesperian plays or other immortal books:

Natural Language Processing (NLP) and Natural Language Generation (NLG) are increasingly used
Teachers and students should understand the basics of those technologies
NLP begins with creation of massive text corpus - all produced strings are statistically inferred from this corpus
Here were used texts from MIPRO CE presentations 2017..2020 (made open-source by Mipro)
NLP algorithms work well only with 'clean' text - no tables, no pictures, no numbers, no links (often is removed also punctuation and text converted to lowercase); all information about authors, affiliations, keywords, acknowledgements etc should be removed.
Text cleaning is a formidable task. Here the .pdf was converted to .doc and then used Microsoft Word macro language.
Text cleaning involves lot of manual work:
"carbage in -> carbage out"
Text may be handled character level, on word level, on paragraph/document level ...
Word level requires several additional operations (stopword removal, lemmetization stemming), therefore here new text generation was done on character level
From the total corpus is counted its vocabulary - words without repetitions (unique words)
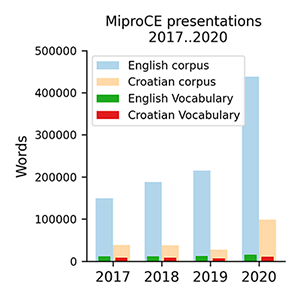
The English (joined) corpus contained 6112294 words (unique words - 25077); the Croatian corpus - 1038619 words (unique - 27049)
Next were counted frequencies of words; in both corpuses the most frequent word was the same:
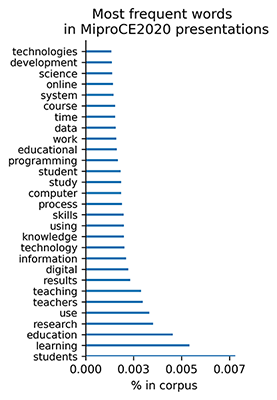
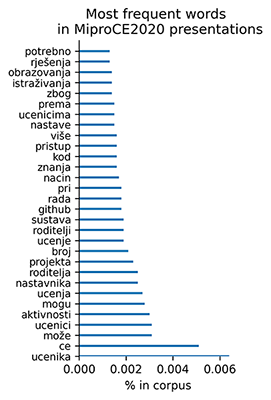
The most frequent words in both corpuses overlap - authors were dicussing the same topics
The common tasks in NLP are
For this are considered entropy of text and subsets of words occuring close to each other - the consequtive words (n-grams) and non-consequtive (BOW - Bags Of Words)
n-gram of a word is a sequency of consequitive n words containg the word
E.g. 3-grams for the word students in text Students like games. Students seek educational games (after converting text to lowercase and removing punctuation) are:
students like games, like games students, games students seek, students seek educational
Entropy shows average amount of information of words (in bits).
The Croatian language is more complex than English: more letters, more word forms etc., thus its entropy is greater, but decreases with bigger phrases. Entropy of single words (unigrams), two consecutive words (bigrams), three consecutive words (trigrams) etc. shows essential difference between English and Croatian languages.
| English | Croatian | |
|---|---|---|
| Vocabulary | 25677 | 27049 |
| Entropy of 1-grams | 6.33 | 8.25 |
| Entropy of 2-grams | 8.2 | 8.06 |
| Entropy of 3-grams | 6.17 | 5.63 |
| Entropy of 4-grams | 4.76 | 4.26 |
| Entropy of 5-grams | 3.83 | 3.41 |
Phrases with high PMI value in English: "does not" (7.86), "has been" (7.76), "Facebook, Instagram, Twitter" (25.95), "In this paper" (15.28), "as well as" (14.23), "can be seen" (14.1), "On the other hand" (24.36), "in the field of" (12.81)
Phrases with high PMI value in Croatian: "strucno usavrš1avanje" (11.43), "Visokog ucilišta" (11.27), "Kljucne rijeci" (11.02), "najmanje jednom, inace" (25.81), "izvorne engleske rijeci" (24.57), "Pitanje NUM Koliko cesto" (29.7)
Phrases can be separated on their occurrence spectrum:
- significant phrases occur in tight 'dumplings' which are unevenly distributed
- common/insignificant phrases are evenly distributed in the whole text
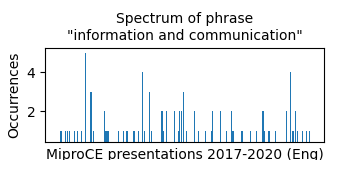
In English corpus the phrase Information and Communication (E = 8.98, PMI = 11.28) was repeated in nearly every presentation (thus common/insignificant):
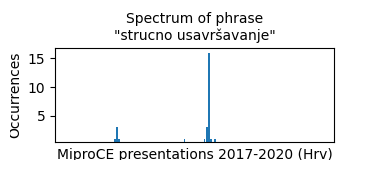
In Croatian corpus the phrase "strucno usavrš1avanje" (Professional Development, E = 8.98, PMI = 11.28 ) was a good canditate for a keyword phrase:
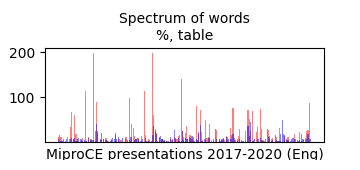
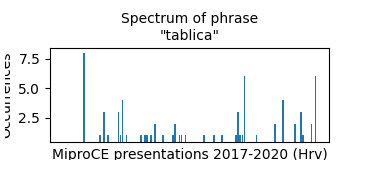
Spectrums of words 'Table', 'Tablica', the percentage sign % show, that the MiproCE is actually already a Data Science conference:
The most fashinating feature of NLP is creation of new texts
If we already have a sequence of words
then the probability of the next word
could be estimated by frequences of similar situations:
This is the key idea of NLP and Machine Learning (ML) in NLP
Prediction quality depends on the length of the predictiong sequence, i.e. how war back goes the prediction memory.
E.g. using short 2-3 word n-grams
produce a text with many repetitions:
pedagogical decisions on using the Internet and the second part of the most important for the purpose of the most important ... …(E=3.45)
They are produced by programs (e.g. Tensorflow, used here) using neural nets
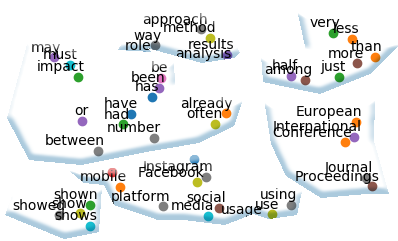
A word vector encodes frequences for other words to occure in its neighbourhood
The text corpus is considered as a vector spase, whose dimension is equal to the number of words in vocabulary
Thus it becomes possible to consider distance between words and present words as points in thie high-dimensional space
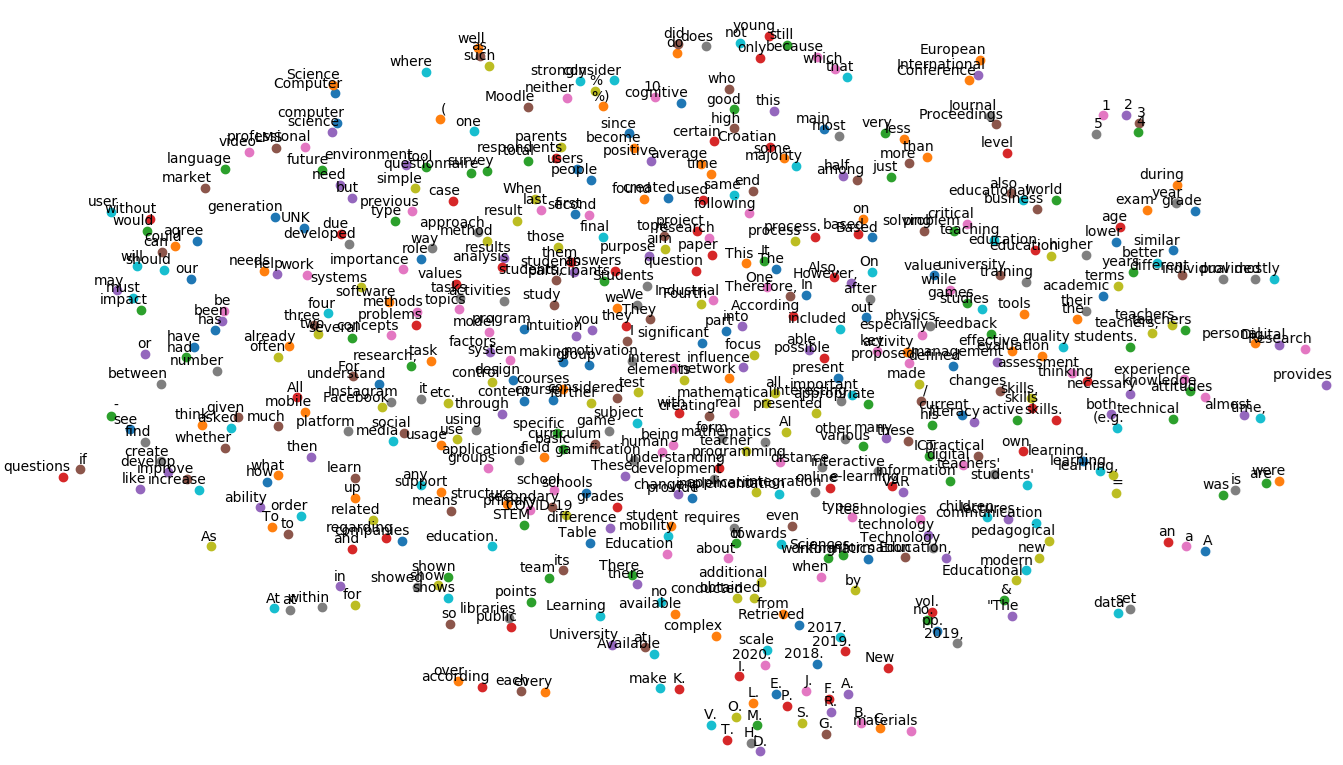
The word cloud created from the English corpus with the Tensorflow program(ca 24 min, vector length = 160 characters)

The word cloud created from the Croatian corpus with the Tensorflow program
Program is able to create new texts resembling human-created one:
Students have the main factor in closed computer literacy in the environment and society. Students can be applied on the tool, such as the most out of expertise, they are also addressed through the profile of the equipment and society of digital technology that is more important than the students.
But program created also total nonsense:
Students are not included in the process of e- learning in the context of the process of teaching and learning.
The 'art' of producing new texts (it has been also used to create new books) is based on statistics: computer combines sequences of characters from a large given text (the text corpus)
Computer does not understand the meaning of the words
e.g. it is impossible to find verbs or phrases which may have some truth value
NLP has nothing in common with traditional linguistic concepts (grammar, parsing, parts of speech) and linguistic theory, it may be called "linquistics without language theory"
NLP is well characterized by the statement from Frederick Jelinek, long-time head of the Center for Language and Speech Processing at Johns Hopkins University:
"Whenever I fire a linguist our system performance improves"
The 'learning' in ML does not change behavior of the computer (if it does, then the computer is severely broken)
The 'learning' in ML is similar to calculating averages
But NLP and ML can be used and are increasingly used for simple natural-language tasks, e.g. plagiarism discovery
Thus teachers and students should understand the basics of these techniques
That's ALL !
Available on-line at 'http://www.ttu.ee/staff/~jaak.henno/Mipro2021/'
Let's all cross fingers for a NORMAL MIPRO sometimes again!