Handling Software Icebergs
Jaak Henno, Tallinn University of Technology, Estonia
Hannu Jaakkola, Tampere University, Pori, Finland
Jukka Mäkelä, University of Lapland, Finland
This presentation is on-line at http://staff.ttu.ee/~jaak.henno/SQAMIA2022/
Humanity is obsessed with GROWTH
For GROWTH are needed resources
The natural resources are running out and the most important resource has become DATA
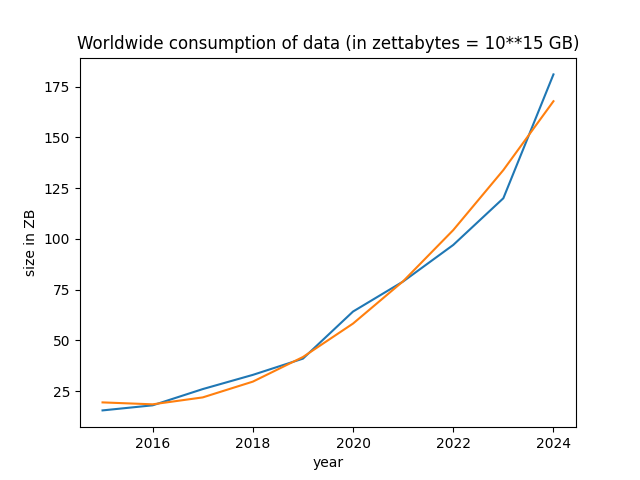
This data is processed by programs.
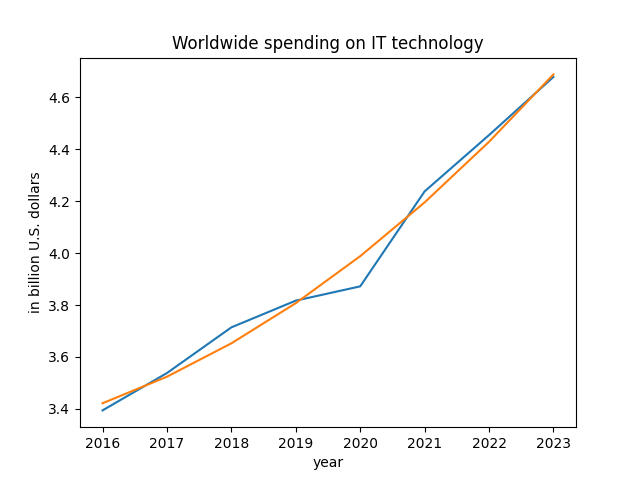
Worldwide spending on IT technology is growing > 5% per year
Software (programs) have become services
Different programs share many components, which
are stored in world-wide cloud storage
The global cloud computing size grows yearly > 19%. The growth of cloud computing in education is expected 25.6%
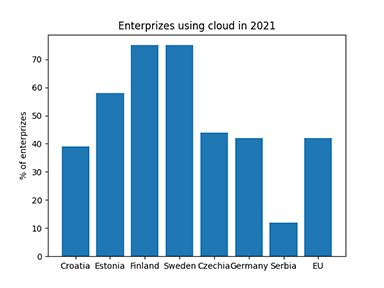
We do not have any more monolithic programs hosted on your own server
Programs are collections of independent components/packages/libraries
Those components/libraries are responsible for 60..99% of program's functionality
Nobody does not know exactly what these inserted components/libraries do
"Modern software development is a study in entropy" (E. Freeman, AWS)
“It has never been more difficult to be a software developer than it is today” (N. Simpson)
Modern software is like icebergs in Arctica – the main part is hidden.
On the following slides are some examples
Example 1
A Python 3 program to create graph diplaying growth of the SQAMIA conference:
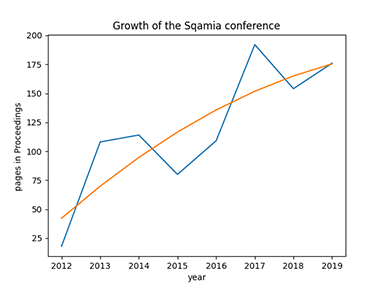
For experienced 'classical' programmers the above code should look rather strange:
no loops ???
The 'classical' program, i.e. using only commands from a programming language without any libraries would have to use several loops – using the x_sqamia iterator, projecting values to axes, solving the system of equations for creating square approximation in order to calculate correlation parameters a2,a1,a0. Totally is hidden the AI (Artificial Intelligence) – calculating the size and visually pleasing placement of axes and their scales.
The whole 'magic' is in the first two lines:
In these two libraries are loaded other libraries, which again load others etc
Thus the script imports alltogether 162 modules (and 28 items appear as MissingModule):
_bootlocale • _collections_abc • _weakrefset • abc • codecs • collections • collections.abc • copyreg • encodings • encodings.aliases • encodings.ascii • encodings.base64_codec • encodings.big5 • encodings.big5hkscs • encodings.bz2_codec • encodings.charmap • encodings.cp037 • encodings.cp1006 • encodings.cp1026 • encodings.cp1125 • encodings.cp1140 • encodings.cp1250 • encodings.cp1251 • encodings.cp1252 • encodings.cp1253 • encodings.cp1254 • encodings.cp1255 • encodings.cp1256 • encodings.cp1257 • encodings.cp1258 • encodings.cp273 • encodings.cp424 • encodings.cp437 • encodings.cp500 • encodings.cp65001 • encodings.cp720 • encodings.cp737 • encodings.cp775 • encodings.cp850 • encodings.cp852 • encodings.cp855 • encodings.cp856 • encodings.cp857 • encodings.cp858 • encodings.cp860 • encodings.cp861 • encodings.cp862 • encodings.cp863 • encodings.cp864 • encodings.cp865 • encodings.cp866 • encodings.cp869 • encodings.cp874 • encodings.cp875 • encodings.cp932 • encodings.cp949 • encodings.cp950 • encodings.euc_jis_2004 • encodings.euc_jisx0213 • encodings.euc_jp • encodings.euc_kr • encodings.gb18030 • encodings.gb2312 • encodings.gbk • encodings.hex_codec • encodings.hp_roman8 • encodings.hz • encodings.idna • encodings.iso2022_jp • encodings.iso2022_jp_1 • encodings.iso2022_jp_2 • encodings.iso2022_jp_2004 • encodings.iso2022_jp_3 • encodings.iso2022_jp_ext • encodings.iso2022_kr • encodings.iso8859_1 • encodings.iso8859_10 • encodings.iso8859_11 • encodings.iso8859_13 • encodings.iso8859_14 • encodings.iso8859_15 • encodings.iso8859_16 • encodings.iso8859_2 • encodings.iso8859_3 • encodings.iso8859_4 • encodings.iso8859_5 • encodings.iso8859_6 • encodings.iso8859_7 • encodings.iso8859_8 • encodings.iso8859_9 • encodings.johab • encodings.koi8_r • encodings.koi8_t • encodings.koi8_u • encodings.kz1048 • encodings.latin_1 • encodings.mac_arabic • encodings.mac_centeuro • encodings.mac_croatian • encodings.mac_cyrillic • encodings.mac_farsi • encodings.mac_greek • encodings.mac_iceland • encodings.mac_latin2 • encodings.mac_roman • encodings.mac_romanian • encodings.mac_turkish • encodings.mbcs • encodings.oem • encodings.palmos • encodings.ptcp154 • encodings.punycode • encodings.quopri_codec • encodings.raw_unicode_escape • encodings.rot_13 • encodings.shift_jis • encodings.shift_jis_2004 • encodings.shift_jisx0213 • encodings.tis_620 • encodings.undefined • encodings.unicode_escape • encodings.unicode_internal • encodings.utf_16 • encodings.utf_16_be • encodings.utf_16_le • encodings.utf_32 • encodings.utf_32_be • encodings.utf_32_le • encodings.utf_7 • encodings.utf_8 • encodings.utf_8_sig • encodings.uu_codec • encodings.zlib_codec • enum • functools • heapq • io • keyword • linecache • locale • matplotlib.pyplot • numpy • operator • pyi_rth__tkinter.py • pyi_rth_inspect.py • pyi_rth_mplconfig.py • pyi_rth_multiprocessing.py • pyi_rth_pkgres.py • pyi_rth_pkgutil.py • pyi_rth_subprocess.py • pyi_rth_traitlets.py • re • reprlib • scipy.stats • sre_compile • sre_constants • sre_parse • tokenize • traceback • types • warnings • weakref
But the 'magic' has cost
A simple Python program reveals, that the imported 162 modules contain 18378 LOC (Lines Of Code)
The difference between 18 LOC in the presented previously program listing with the all LOC in imported modules can be represented by index of visibility:
Thus students can inspect only 0.0000979431-th size part of the above ('loop-less') program
And from the code presented above it is not clear, what should be done with the program for the above graph in order to include two missing SQAMIA years 2020, 2021 - if x_data, y_data have different size, then how to mark the corresponding values?
Example 2
The introduction to library React ("React Getting Started" in popular Web W3Schools) seems rather short :
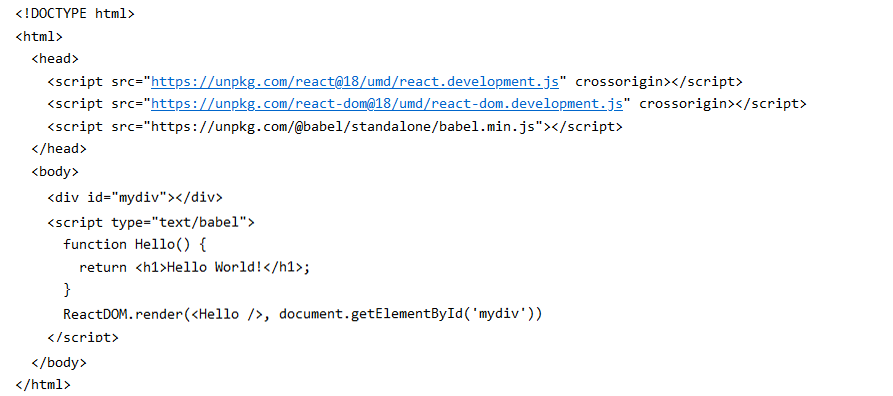
But loaded above three Javascript files contain 73571+3358+26275 = 103204 lines of JavaScript code
The 103204 lines of code imply index of visibility:
This large amount of invisible/inspectable code is not needed, since the following program will produce exactly the same output (without any external scripts):
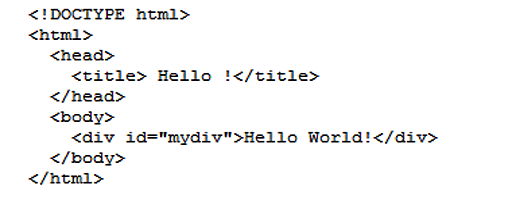
Example 3
Three lines of Tensorflow example from Google load three libraries:
These libraries import 158 other modules:
_bootlocale • _collections_abc • _weakrefset • abc • codecs • collections • collections.abc • copyreg • encodings • encodings.aliases • encodings.ascii • encodings.base64_codec • encodings.big5 • encodings.big5hkscs • encodings.bz2_codec • encodings.charmap • encodings.cp037 • encodings.cp1006 • encodings.cp1026 • encodings.cp1125 …•
But the real complexity of this program comes from code: Tensorflow creates a model with nearly 4 million parameters:
Pandemic has forsed many IT students to self-learning from WWW
Self-learning students can not understand the 'hidden-layers' of modern software
The examples/tutorials in WWW are recepies, where the 'inner working' is not explained
Thus the pandemic has created 'top-down' programmers:
First: import all libraries (what seem to be usefull)
Then: start googling
They do not undersand the problem or how to solve it
Teachers task after pandemic: reveal to students the hidden parts of modern software icebergs.
This presentation is on-line at http://staff.ttu.ee/~jaak.henno/SQAMIA2022/
In real world the situation is much worse
Software of world-wide companies (e.g. Amazon - depicted on background) use microservices on API-s, dockers/Kubernetes/OpenShift... (instaed of programming languages commands) and the Cloud providers are providing for users only Frameworks(i.e. menus), not real programming languages (pre-programmed menus are safer)
The complexity of programs is growing far quicker than the ability of programmers - even if we send all students to STEM
history - who needs it, it has already been?
literature - who has time to read invented stories?
art - we all draw in pre-school age...
...