|
|
|
|
|
 w1vw2
w1vw2  ( - tühi sőna), kui algussümbol Xo ei esine ühegi produktsiooni paremal pool. w' rahuldavad tingimust |w|
( - tühi sőna), kui algussümbol Xo ei esine ühegi produktsiooni paremal pool. w' rahuldavad tingimust |w| 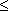 |w'| v, kus X on mitteterminal; Ya a
|w'| v, kus X on mitteterminal; Ya a
Saab näidata, et regulaarsete grammatikate poolt genereeritud keeled saab kirjeldada ka grammatikatega, mille produktsioonid on parempoolsed, s.t. kujul
X aY vői X a
Selles klassifikatsioonis iga järgmine klass kuulub eelmisesse (s.t. näiteks regulaarsed grammatikad rahuldavad kőiki kontekstivabade grammatikate klassi nőudeid), selleärast laieneb Chomsky klassifikatsioon loomulikul viisil ka keeltele: keelt nimetatakse klassi i (i=3,2,1,0 ) keeleks ehk vastavalt regulaarseks, kontekstivabaks, kontekstitundlikuks, rekursiivselt loenduvaks, kui teda saab genereerida klassi i grammatikaga ja ei saa genereerida klassi i+1 (s.t. rangema, kitsama klassi) grammatikaga.
Vaatamata liigituse formaalsele alusele (produktsioonide kuju) on Chomsky klassifikatsioonil sügav sisu. Paljud keelte käsitlemisel olulised omadused, näiteks keeli tunnistava programmi töökiirus ja mäluvajadus jne on seda paremad, mida lihtsama klassi keeli vaadeldakse. Sellepärast püütakse translaatorite alametappidel (leksiline analüüs, süntaksi analüüs jne) kasutada keeli, mis on kas regulaarsed vői kontekstivabad. See vőimaldab vastava etapi kirjeldada lähteteksti ühekordse vasakult-paremale läbivaatamisena, kusjuures ajaduse korral vaatatakse enne mingi teisenduse tegemist käsitletavast sümbolist ka paar eespool tulevat sümbolit (nn look-ahead) ja seega sooritada vastava etappi (peaaegu) lineaarse kiirusega, s.t. nii, et programmi töötaktide arv on vőrdeline sisendteksti pikkusega.
1. Millisesse klassi kuulusid eespool vaadeldud eesti keele lihtlause ja lihtsa programmeerimiskeele süntaksi kirjeldused?