Eespoolvaadeldud Pisi-Algoli kirjeldus määras selle keele süntaksi - millise vormiga on programm (käskude jada, kus iga käsk lõpeb lõpumärgiga ; ) ja millise vormiga on käsud (näiteks omistamine on kujul Identifikaator := Avaldis).
Lekseemide tasemel on keele struktuur märksa lihtsam. Leksiliselt võib programmi kirjeldada kui kolme liiki lekseemide (token) jada:
sõnad (identifikaatorid ja keele nn. võtmesõnad IF, THEN,...)
arvkonstandid (täisarvud)
eraldajad: tühikud, sulud, käsu lõpumärgendid ; , omistusmärk := , aritmeetiliste ja loogiliste operatsioonide märgid + - * / = /= > < >= <=.
Kunagi ei ole järjest kaks sõna või kaks arvu - siis poleks võimalik otsustada, kus lõpeb esimene ja algab teine, seega sõna ja arvkonstandi järel peab alati olema eraldaja; eraldajaid võib üksteisele järgneda kuitahes palju. Enamasti on eraldajad ühesümbolilised, kuid on ka mõned kahesümbolilised: omistusmärk := (: üksi ei ole eraldaja!) ja loogiliste võrdlusoperatsioonide märgid /= >= <=. Sõnade kirjaviis on nagu identifikaatoritel: nad peavad algama tähega, edasi võivad tulla nii tähed kui ka numbrid (keele võtmesõnad eraldatakse hiljem, võrreldes loetud sõna võtmesõnade tabeliga).
Sellise struktuuriga leksikat kirjeldab grammatika, mille terminalide tähestik on (loetavuse huvides ei ole tähestiku sümbolid esitatud literalidena, s.t. nagu programmeerimiskeeltes - apostroofide ' ' vahel):
T = {A,B..Z,0,1 ..9,+,-,*,/,=,<,>,(,),;,' '}
mitteterminalid onV = {PROGRAMM, ERALDAJA, SÕNA, ARV, OP, TÄHT, NUM}
ja produktsioonid onPROGRAMM  (ERALDAJA |
SÕNA ERALDAJA | ARV ERALDAJA )+
(ERALDAJA |
SÕNA ERALDAJA | ARV ERALDAJA )+
SÕNA TÄHT (TÄHT | NUM )*
ARV
NUM +
ERALDAJA OP | ( | ) | := | ; |' '|
OP + | - | * | / | = | < | >
TÄHT A .. Z
NUM 0 .. 9
Selle keele lekseemid tunnistab lõplik automaat 
Siin ![]() tähistab alamautomaati
tähistab alamautomaati
 ,
,
![]() tähistab alamautomaati
tähistab alamautomaati
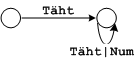
ja![]() tähistab alamautomaati
tähistab alamautomaati
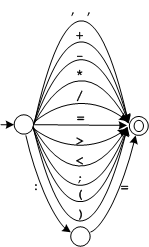 .
.
Sellise keele leksika formaalse kirjelduse alusel on lihtne kirjutada programmi, mis sooritab keele leksilist analüüsi (skanner). Lihtne on näha, et
FIRST(SÕNA) = {A..Z}
FIRST(ARV) = {0..9}
FIRST(ERALDAJA) = {+ , -, * , / , = , < , > , (, ), :, ;, ' '};
define function absolute-value(x ::
import std.stdio;
void main(char[][] args)
{
writefln("Hello World, Reloaded");
// auto type inference and built-in foreach
foreach (argc, argv; args)
{
// Object Oriented Programming
CmdLin cl = new CmdLin(argc, argv);
// Improved typesafe printf
writefln(cl.argnum, cl.suffix, " arg: %s", cl.argv);
// Automatic or explicit memory management
delete cl;
}
// Nested structs and classes
struct specs
{
// all members automatically initialized
int count, allocated;
}
// Nested functions can refer to outer
// variables like args
specs argspecs()
{
specs* s = new specs;
// no need for '->'
s.count = args.length; // get length of array with .length
s.allocated = typeof(args).sizeof; // built-in native type properties
foreach (argv; args)
s.allocated += argv.length * typeof(argv[0]).sizeof;
return *s;
}
// built-in string and common string operations
writefln("argc = %d, " ~ "allocated = %d",
argspecs().count, argspecs().allocated);
}
class CmdLin
{
private int _argc;
private char[] _argv;
public:
this(int argc, char[] argv) // constructor
{
_argc = argc;
_argv = argv;
}
int argnum()
{
return _argc + 1;
}
char[] argv()
{
return _argv;
}
char[] suffix()
{
char[] suffix = "th";
switch (_argc)
{
case 0:
suffix = "st";
break;
case 1:
suffix = "nd";
break;
case 2:
suffix = "rd";
break;
default:
break;
}
return suffix;
}
}
 ©2004-2013 Jaak Henno
©2004-2013 Jaak Henno