Translaatori esimesel etapil, leksilises analüsaatoris ( skanneris) kasutatakse formaalsete grammatikate kõige esimest, kõige lihtsamat klassi - regulaarseid grammatikaid. Skannerile esitatakse lekseemide kirjeldus regulaarsete avaldistena; ta skaneerib transleeritava teksti (üks kord, vasakult paremale, ilma tagasipöördumisteta) ja leiab skaneerimise käigus tekstist talle esitatud regulaarsetele avaldistele vastavad lekseemid.
Osutub, et lekseemi kirjeldava regulaarse avaldise r põhjal võib automaatselt koostada
programmi, mis kontrollib loetavat sisendsümbolite jada w ja käivitab protseduuri Accept, kui w  L(r)ja protseduuri RecognitionException, kui w
L(r)ja protseduuri RecognitionException, kui w  L(r) . Sellisest sisendi tunnistajast
(recognizer), s.t. sisendi süntaktilist korrektsust kontrollivast
programmist on hiljem lihtne väljundit moodustavate tegevuste
lisamisega saada kogu skanner.
L(r) . Sellisest sisendi tunnistajast
(recognizer), s.t. sisendi süntaktilist korrektsust kontrollivast
programmist on hiljem lihtne väljundit moodustavate tegevuste
lisamisega saada kogu skanner.
Regulaarsele avaldisele r vastava programmilõigu L(r) defineerimisel kasutatakse abifunktsioone FIRST, FOLLOW ja DIRSYMB.
FIRST(r) arvutab regulaarse avaldisega r määratud keele L(r) sõnade algussümbolite hulga, näiteks reaalarvu algusosa kirjeldava regulaarse avaldise r = (0..9)+ . (0..9)* e | e | . (0..9)+ e jaoks
FIRST(r) = {(0..9), e, . }
FOLLOW(r) arvutab regulaarse avaldise r parempoolse konteksti, s.t. kõigi r poolt genereeritud sõnadele järgneda võivate sümbolite hulga, näiteks reaalarve kirjeldavas regulaarses avaldises
( (0..9)+ .
(0..9)* e |
e | . (0..9)+
e ) ( [+ | -] (0..9)+
| (0..9)+ )
FOLLOW( (0..9)+
. (0..9)* e
| e | . (0..9)+
e ) = {+, -, (0..9)}
DIRSYMB(r) erineb FIRST(r)-st vaid siis, kui regulaarne avaldis r võib genereerida ka tühja sõna Ø (see juhtub tavaliselt vaid iteratsioonioperaatori * kasutamisel). Sellisel juhul DIRSYMB(r) sisaldab peale FIRST(r) ka FOLLOW(r), s.t. avaldise e poolt genereeritud sõnadele järgneda võiva terminaalse stringi esimese sümboli (seega ka DIRSYMB väärtus sõltub avaldise r kontekstist). Näiteks kui reaalarvude lõpposa kirjeldada eespooltoodud avaldise
[+ | -](0..9)+ | (0..9)+
asemel veidi teisiti (vigaselt, sest võimaldab vaid märgi + või - ilma et sellele järgneks ühtegi numbrit, kandilised sulud [ ] tähistavad alamavaldist, mis võib olla, aga võib ka puududa):
[+ | -] (0..9)*
siis selles kontekstis
DIRSYMB([+ | -]) = {+, -, (0..9), #}
Märk # on sisendi lõpusümbol; see lisatakse iga regulaarse avaldisega määratud sõna lõppu; siin see saadakse juhul, kui kogu avaldis DIRSYMB([+ | -]) = {+, -, (0..9), #} midagi ei genereeri. Kui reaalarvu lõpuosa oleks kirjeldatud korrektselt regulaarse avaldise
[+ | -] (0..9)+
abil, kehtiksDIRSYMB([+ | -]) = {+, -, (0..9)}
Regulaarsetele (alam)avaldisele e vastav programmilõik defineeritakse, jälgides regulaarse avaldise definitsiooni; programmis CH on char-tüüpi muutuja, mille väärtuseks alamprotseduur READ annab sisendteksti järgneva sümboli; ERROR on alamproceduur, mis käivitatakse sisendtekstis leitud vea salvestamiseks. Järgnevates programmilõikudes on kasutatud programmeerimiskeele Ada95 süntaksit.
Avaldisele 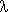 vastab programmilõik
vastab programmilõik
if CH FOLLOW()
then SKIP -- tühi
operaator
else ERROR
end if ;
Avaldisele x VT vastab programmilõik
if CH = x
then READ else ERROR
end if ;
Avaldisele
(r1 | r2 |... | rn)
vastab programmilõik
case CH is
when DIRSYMB(r1)  A(r1)
A(r1)
when DIRSYMB(r2)
A(r2)
...
when DIRSYMB(rn)
A(rn)
end case;
Avaldisele
r1 r2...rn
vastab programmilõik
A(r1) A(r2) ... A(rn)
Eelmise erijuht: avaldisele rn vastab programmilõik
for i from 1 to n loop
A(r)
end loop;
Avaldisele r* vastab programmilõik
while CH in FIRST(r) loop
A(r)
end loop;
Avaldisele r+ vastab programmilõik
loop
A(r)
exit when not(CH in FIRST(r))
end loop;
Regulaarsele avaldise jaoks saab selle poolt genereeritud sõnu tunnistava programmilõigu üheselt koostada vaid siis, kui see avaldis rahuldab ELL(1) tingimusi:
Et illustreerida neid programmilõike täis- ja reaalarvude tunnistamisel, defineerime täis- ja reaalarvudes esinevate märkide jaoks Ada95 andmetüübid
type REAL_CHAR is ('0', '1', '2', '3', '4', '5',
'6', '7', '8', '9', 'e', '.', '+', '-');
subtype NUM is REAL_CHAR range '0'..'9';
subtype SIGN is REAL_CHAR range '+'..'-';
Muutuja CH (sisendist loetud
sümbol) väärtus on kõigi nende programmilõikude käivitamisel mingi
vastava regulaarse avaldisega määratud sisendjada esimene sümbol, s.t.
regulaarsele avaldisele r vastava
programmilõigu käivitamisel CH FIRST(r). Ada-s on seda lihtne
kontrollida süsteemipredikaadi in
abil, näit CH in SIGN on tõene
vaid siis, kui muutuja CH väärtus
on kas '+' või '-'.
Näiteks täisarvu kirjeldavale regulaarsele avaldise (0..9)+ vastab täisarvu tunnistav programmilõik
loop
READ
exit when not(CH in NUM)
end loop;
Kui reaalarv oleks määratud veidi lihtsama regulaarse avaldisega (see on kolme regulaarse avaldise korrutis)
(0..9)+ . (0..9)+
siis ülalesitatud reeglite järgi (ja veidi optimiseerides) saame programmilõigu loop
READ
exit when not(CH in NUM)
end loop;
if CH = '.'
then READ else ERROR
end if;
loop
READ
exit when not(CH in NUM)
end loop;
((0..9)+ . (0..9)* e | e | . (0..9)+ e ) ( [+ | -] (0..9)+ )
põhjal programm reaalarvude tunnistamiseks. Avaldis  Const |
Avaldis + Const | Avaldis - Const
Const |
Avaldis + Const | Avaldis - Const
Const (0..9)+
objId ![]() number | character | string | symbol | boolean | paar |
nimistu | vektor
number | character | string | symbol | boolean | paar |
nimistu | vektor
 ©2004-2013 Jaak Henno
©2004-2013 Jaak Henno