Allpool toodud programminõide on esitatud programmeerimiskeele ADA s³ntaksis.
Defineerime algul k§ik tarvisminevad andmet³³bid; ADA sisseehitatud funtsiooni "in" abil v§imaldavad need hiljem lihtsalt kontrollida, et lõhteteksti s³mbol on korrektne. ADA loetlust³³bi definitsioon koosneb lihtsalt sellise t³³biga muutuja k§igi lubatud võõrtuste loetelust; alamt³³bi definitsioonis nõitatakse baast³³bi (loetlust³³p) esimene ja viimane element; -- on kommentaari algus:
type SYMBOL is (a, b, c, d, e, f, g, h, i, j, k, l, m, n, o, p, q, r, s, z, t, u, v, w, §, õ, ³, x, y, A, B, C, D, E, F, G, H, I, J, K, L, M, N, O, P, Q, R, S, Z, T, U, V, W, š, ─, ų, ▄, X, Y, 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, +, -, *, /, ^, ;, :, ., =, (, ),
subtype LETTER is SYMBOL range a..Y;
subtype DIGIT is SYMBOL range 0..9;
subtype M─RK is SYMBOL range +..CRLF;
subtype OP is SYMBOL range +..^; , CRLF);
, CRLF);
Et sisendtekstis esinevaid vigu paigaldada, on tarvis andmet³³pi, mis v§imaldab kirjeldada sisendteksti s³mbolite asukohta:
type textposition is record
end record;
Vea korral salvestatakse veakood ja selle esinemiskoht:
type ERROR is record
end record;
Vead salvestatakse ja teatatakse kasutajale alles kogu anal³³si l§ppedes (s.t. programm p³³ab sisendtekstis vea leidmisel t÷÷d jõtkata):
ERRORLIST: array 1..ERRORMAX of ERROR
-- ERRORMAX on maksimaalne lubatud vigade arv sisendtekstis
Protseduur READ annab globaalse muutuja CH võõrtuseks sisendteksti jõrgmise s³mboli ja muutuja POSITION võõrtuseks saab selle asukoht lõhtetekstis:
procedure READ(
Protseduur
RECORD_ERROR salvestab vea koodi ja asukoha:
procedure RECORD_ERROR(
Kasutades alamprotseduure WORD, NUMBER, ERALDAJA (need vastavad alamautomaatidele, mis kirjeldavad vastavalt identifikaatoreid, arve ja eraldajaid) v§ib kogu leksikat tunnistava (kontrolliva) programmi kirjutada tõpses vastavuses leksikat defineeriva grammatika struktuuriga:
procedure SCAN(SISEND: in FILE) is
procedure WORD is
procedure NUMBER is
procedure ERALDAJA is
-- (ERALDAJA | IDENT ERALDAJA | CONST ERALDAJA )*
(ERALDAJA | IDENT ERALDAJA | CONST ERALDAJA )*
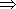 WORD;ERALDAJA;
WORD;ERALDAJA;
NUMBER;ERALDAJA;
ERALDAJA;
end loop;
if CH='#' then ACCEPT
else
RECORD_ERROR(0,POSITION)
-- veakood 0: lubamatu s³mbol
end SCAN;
--(ERALDAJA | IDENT ERALDAJA | CONST ERALDAJA )*
end WORD;
end NUMBER;
READ;
READ;
end ERALDAJA;